Seq2Seq
Sequence To Sequence
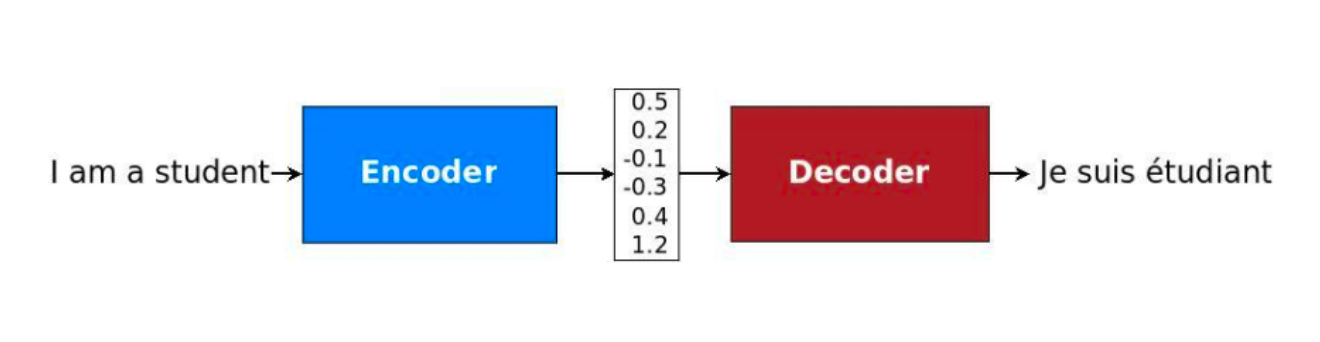
Encoder-Decoder (Seq2Seq) made it possible to map input sequences to output sequences of different lengths, because "I want a coffee with milk" and "Yo quiero cafe con leche" have different total lengths of words (even if it's just "a"). This also allowed for taking in entire photos, and outputting a text representation (video captioning), outputting bounding box anchors of objects (object detection), and many other future architectures
Most Seq2Seq models are a combination of conditional language models with long range encoders that build up context, and auto-regressive decoders for generating text outputs. These decoders can be greedy and simply choose the most likely token, or then can perform general search over future text outputs as well
Encoder Decoder
Over time word embeddings and sentence embeddings were gaining traction, but things became awkward when there wasn't a fixed length 1:1 mapping from input to output. "My name is Luke" "Me llamo Luke" isn't a 1:1 mapping, and so machine translation and other similar tasks started hitting these sequence-to-sequence roadblocks
Ultimately, the thought process was to build an architecture with 2 parts:
- Encoders dealt with variable length input sequences to transform it into a fixed state / fixed size vector
- Decoders would take that fixed size hidden state, and output a variable length output
These could utilize Recurrent NN's for variable length input and output, or really any other architecture that allowed for repeating predictions, and then the mapping between variable length sequence to variable length sequence could be achieved
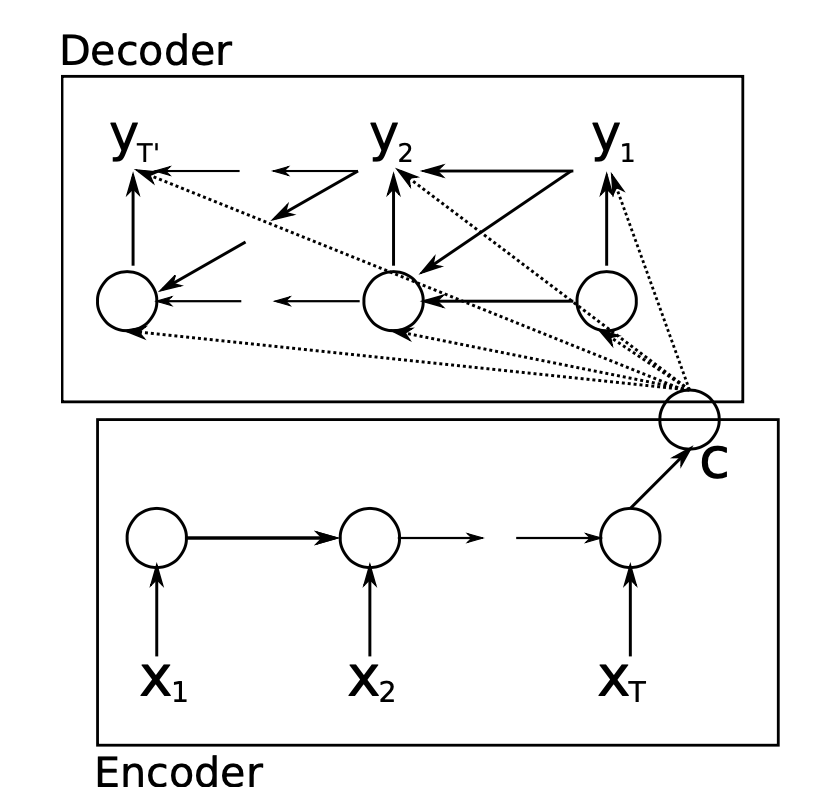
The generic framework proposed in initial papers has:
- Encoder RNN processes the input sequence of length to compute a fixed length context vector
- This context vector is usually just the final hidden state of the encoder, or some function of the hidden states if that's desired
- This context vector is supposed to encode all relevant information, signals, etc about the input vector
- Decoder RNN process uses the context vector to produce a target sequence of length
- The context is passed to every hidden state of the decoder, the decoder RNN uses this information to produce the target sequence of length , which can of course vary from
Encoder
The encoder portion is really just a straightforward RNN! It's main objective is to output a hidden state context vector , and to be able to handle varying length inputs and preserve their signal in
Each input (let's say one single sentence) will have multiple words / tokens, where each token is represented by a fixed size embedding (most likely something from Word2Vec) - each input feature vector can be represented as a static word embedding for the rest of this article
At any time step , the RNN transforms the input feature vector for token , and also uses the hidden state to create the current hidden state
This will happen over each of the input tokens, and ultimately we will use the set of hidden states to create the final hidden state
can be an identity function, which means is just the final hidden state, or it can aggregate all of the hidden states, use some weighted aggregation, etc
The example above utilizes a unidirectional RNN, but the same encoding process can be done with a bi-directional encoder as well. As long as it makes sense in the context of the overall architecture, we might as well utilize the extra information! In that case we would simply do the unidirectional pass in both directions, and then any hidden state would be a function of it's 2 unidirectional passes
Below python snippet showcases how you can use an Embedding layer (word2vec or modern equivalent) along with some generic rnn calls to create a forward pass of an encoding layer
Show Python Script
class Seq2SeqEncoder(d2l.Encoder): #@save
"""The RNN encoder for sequence-to-sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(embed_size, num_hiddens, num_layers, dropout)
self.apply(init_seq2seq)
def forward(self, X, *args):
# X shape: (batch_size, num_steps)
embs = self.embedding(X.t().type(torch.int64))
# embs shape: (num_steps, batch_size, embed_size)
outputs, state = self.rnn(embs)
# outputs shape: (num_steps, batch_size, num_hiddens)
# state shape: (num_layers, batch_size, num_hiddens)
return outputs, state
Decoder
The decoder is a much more interesting part to focus on, as it starts to incorporate many new architectures that will eventually underpin things like Self Attention and contextual embeddings
At a high level, the decoder will typically focus on the 3 things below:
- Feed source and previously generated target words into a network
- Get vector representation of context (both source and previous target) from the networks decoder
- From this vector representation, predict a probability distribution for the next token
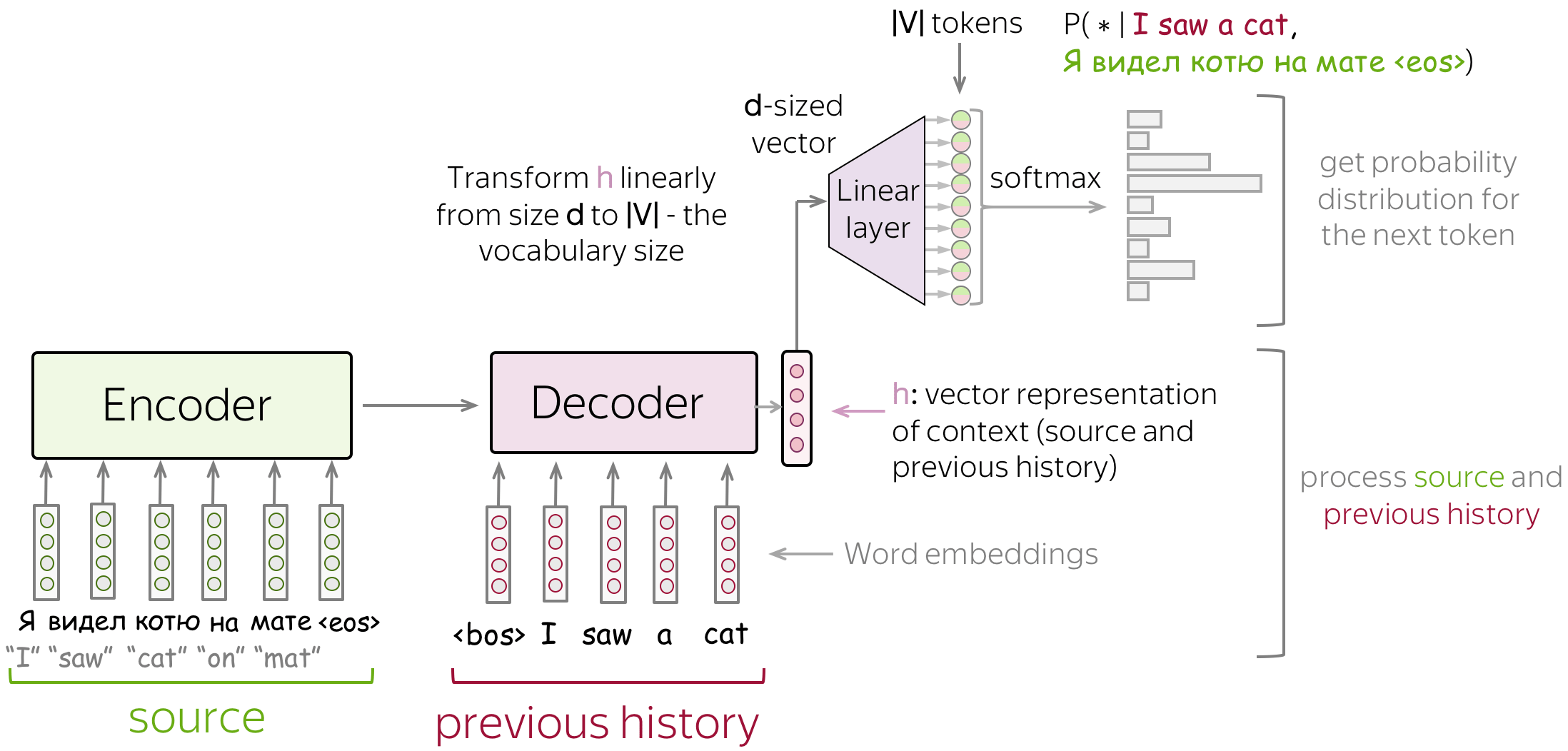
At each time step the decoder assigns a probability to each possible token in the vocabulary, and the probability is conditioned upon previous output tokens , the previous hidden state , and the encoder hidden state context variable
After getting the hidden state for current time , we can use an output layer and softmax operation to compute the predictive distribution. This output layer is typically used to go from the underlying dimension of the decoder NN into the vocabulary size we need to predict
P(y_{[t']} | y_{[0]}, y_{[1]}, ... , y_{[t' - 1], c) = f(h_{[t - 1]}, y_{[t' - 1]}, c)Below python script showcases some of this:
- Use the last hidden state of the encoder to initialize the hidden state of the decoder
- Therefore, RNN encoder and decoder have the same number of layers and hidden units
- Hidden context is concatenated with decoder input at all time steps to ensure is able to spread it's information around everywhere
- The thought here is this context variable is so vital, we shouldn't lose it by passing it through hidden states and instead should allow it to be used at each step
- The output layer is a fully connected layer to predict the probability distribution of the output token over all vocabulary entries
Show Python Script
pytorch
mxnet
jax
tensorflow
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(embed_size+num_hiddens, num_hiddens,
num_layers, dropout)
self.dense = nn.LazyLinear(vocab_size)
self.apply(init_seq2seq)
def init_state(self, enc_all_outputs, *args):
return enc_all_outputs
def forward(self, X, state):
# X shape: (batch_size, num_steps)
# embs shape: (num_steps, batch_size, embed_size)
embs = self.embedding(X.t().type(torch.int32))
enc_output, hidden_state = state
# context shape: (batch_size, num_hiddens)
context = enc_output[-1]
# Broadcast context to (num_steps, batch_size, num_hiddens)
context = context.repeat(embs.shape[0], 1, 1)
# Concat at the feature dimension
embs_and_context = torch.cat((embs, context), -1)
outputs, hidden_state = self.rnn(embs_and_context, hidden_state)
outputs = self.dense(outputs).swapaxes(0, 1)
# outputs shape: (batch_size, num_steps, vocab_size)
# hidden_state shape: (num_layers, batch_size, num_hiddens)
return outputs, [enc_output, hidden_state]
Both parts are jointly trained to maximise the conditional log-likelihood, where denotes the set of model parameters and (input, output) pairings from the training set with size
This best probability is usually found via the beam search algorithm, whose core idea is that on each step of the decoder you track the most probable partial translations (usually called hypotheses)
Training
These models are trained to predict probability distributions of the next token given previous context (source and previous output target tokens). Understanding that they simply predict probability distributions is important! Their evaluation is based on distribution comparisons, and then the actual generation done via search algorithms are completely split out from prediction output
This idea took me a long time to internalize, so I'll bold italicize it a bunch
Formally for training, assume:
- Training instance with source
- Target
- At timestamp the model predicts a probability distribution
- The target at thsi step is
- i.e. we want model to assign probability 1 to the correct token and zero to the rest
- The standard loss for probability comparisons is cross entropy
These target instances are from cleaned web scraped content, human reviewed content, etc
Inferece
Inference and generating actual output tokens is an expensive task. The output probability distributions the model outputs aren't the end result - they need to have a word chosen from them!
The formal definition of what needs to be maximized:
So how can you actually find ? Generating one at a time might incur incorrect results, especially if the desired token 2 steps away depends on a current token being predicted that isn't the top probability. For example at time , the sentence may be "my name", and next token may have the highest probability, given the encoded context vectors, of "Luke", whereas we actually need it to be "is Luke" over 2 steps
This can be formulated as hypotheses, where each potential set of future words chosen, all of the combinations, are a set of hypotheses we could output. So what are the main strategies searching over this result space and generating actual tokens to output? It all comes down to time complexities and the efficiency of models
For any time the decoder outputs predictions representing the probability of each token in the vocabulary coming next in the sequence, and it's conditioned on the previous tokens, cVT'$
Greedy Search would simply choose the token with the highest conditional probability from . However, the greedy search finds the sequence of most likely tokens, whereas the objective of Seq2Seq is actually to find the most likely sequence. The sequence of most likley tokens is typically not equal to the most likely sequence altogether
Exhaustive Search would look to generate all possible combinations of output tokens, and then run probability distributions over all combinations in the resulting set. If there are 100 words in our vocabulary with max sentence size of 20, we'd need to run simulations, which is well beyond the capabilities (and frankly wasteful)
So greedy search is extremely cheap at , but is sub-optimal, and exhaustive search is extremely compute intensive, and there are many strategies inbetween, like beam search, which looks to bridge the gap inbetween
Greedy Decoding
This is the most straightfoward, cheapest, and more efficient decoding strategy. At each time step you simply pick the token with the highest probability based on encoding state and previous vectors without any searching
It's flawed in that the best token at the current step doesn't always necessarily lead to the best, or correct, output sequence. That's formalized by the max over products not being equal to the product over maxes
Beam Search
Beam search keeps track of the most probably hypotheses
Beam search is a method for decoding a sequence given an auto-regressive function that outputs a probability distribution over the next possible symbols - in this scenario it's specifically focusing on how to choose a word from an output probability distribution in an encoder-decoder seq2seq model architecture
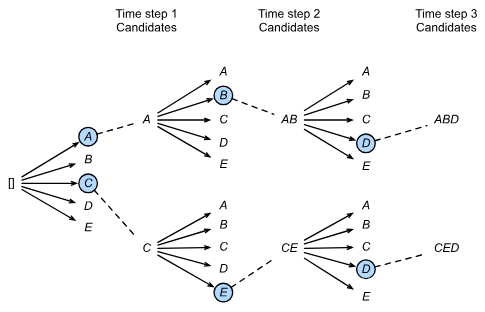
Beam search itself is characterized, mostly, by a hyperparameter beam size k
- At step 1 we choose tokens with the highest predicted possibilities
- At step 2, based on the initial candidates, we choose candidates from each of those
- And so on and so forth, ultimately selecting candidate output sequences with the highest predicted possibilities from the possible choices
Below shows beam size of 2 with a total output sequence of length 3. From this the set of output sequences would be A, C, AB, CE, ABD, and CED, and for our predicted output we would choose the highest probability sequence from this list
Prediction and Evaluation
To predict the actual output sequence at each step, the predicted token from the previous time step is fed into the decoder as an input in the current step
When a new prediction is ready to be made, there are many ways to actually choose which token from the distribution we should utilize - the most intuitive and common approach would be to just take the word with highest probability. It's a pretty straightforward architecture, seems intuitive, etc, and it's fine but there are also more sophisticated techniques like beam search
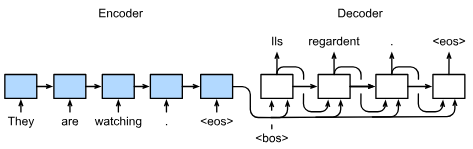
The initial token fed into the sentence is a special token like <bos> meaning Beginning Of Sentence, and then when the decoder finally predicts <eos> the sentence generation will stop
After this is done, how can we evaluate if that word is correct? What if we chose America instead of USA as the output token? Is that "wrong"? Most of the time the Bilingual Evaluation Understudy (BLEU), which was proposed for evaluating machine translation results, is the most commonly used dataset for evaluating Seq2Seq models like this. It works by looking over n-grams in the predicted sequence, and BLEU allows evaluation on whether any n-gram appears in the target sequence
If is the precision of an n-gram, which is defined as the ratio of the number of matched n-grams in the predicted and target sequences to the number of n-grams in the predicted sequence, then we can define metrics as
Which gives BLEU as
A better explanation would be, given a target sequence and a predicted sequence of , we have:
If the predicted sequence is the same as the target sequence, the BLEU score is 1, and the length of the n-gram matters because matching a longer n-gram is harder than a shorter one