T5
T5
Text-To-Text Transfer Transformer (T5) is trained on Colossal Clean Crawled Corpus (C4) via span corruption (i.e. remove portions of sentences) for the model to predict, and this led to a foundational model built on the encoder-decoder architecture which has great results for Seq2Seq tasks. Compared to models like BERT, which can only output a span of the input or a class label, T5 reframes all NLP tasks into a unified text-to-text format, where inputs and outputs always consist of text strings. As a result, the same model, loss function, and hyperparameters can be used on any NLP task, such as machine translation, document summarization, question answering, and classification tasks like sentiment analysis. T5 can even be applied to regression tasks by training it to predict the string representation of a number (and not the number itself
T5 could hypothetically create long strings of generative output, but it's architecture and design is heavily focused on generating output via encoder context, and so it's fairly "bounded" in it's output representations compared to GPT models
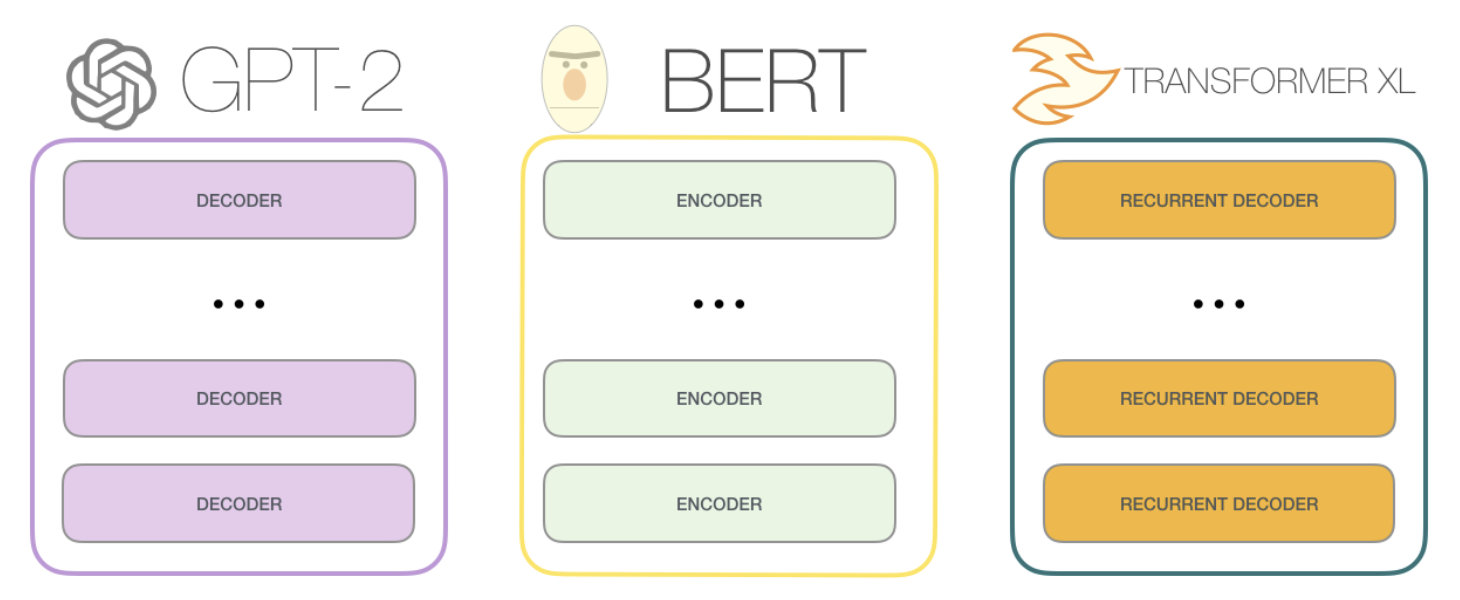
BERT can be seen as stacked encoders, T5 aims to combine the good parts of encoders and decoders, while GPT are stacked decoders
There's a great example of utilizing an event loop in Python / Go and C++ infrence process on GPU's in a monolithic way to have 8 models running on a single VM to handle a high concurrency and low latency inference system in a monolith. This ties into showcasing Triton, which is an open source NVIDIA software package that handles all of this for us on NVIDIA GPU's