Embeddings
Embeddings
Embeddings are dense vector representations of objects - typically you use them for Documents, Queries, Users, Context, or Items...but they can really be used to represent anything
History
- In the past there have been many ways of creating embeddings
- Encoders
- One Hot Encoding: When you would replace categorical variables with vectors of sparse 0's and a single 1 representing the category
- Binary Encoders: Converts categorical variables into binary code - similar to One Hot Encoding, except you basically pick an ID that incrementally increases for new categories
- Collaborative Filtering is discussed later on
- Word2Vec
- Doc2Vec
- Node2Vec!
- etc...
Categorical Embeddings
ML models typically need fixed length vectors as their input, and over time they look to create distributions over these input
With a dictionary of words it's hard to think about the best way to set up these fixed length vectors, and the first attempt was One Hot Encoding where you'd simply have a sparse vector with 1's all around where your words were
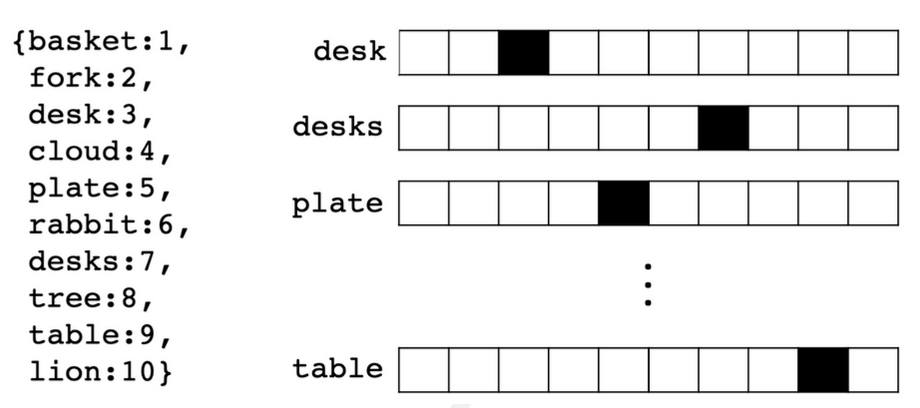
- One-Hot Encoding represents orthonormal basis of vectors, and typically is useful for categorical variables but becomes infeasible if you try to use it for text features
- Label Encoding is similar to One-Hot Encoding, except you use an incremental ID for each of the categories
Pitfalls
Common pitfalls associated with these categorical embeddings is that:
- They create humongous vector spaces of orthogonally independent vectors
- Essentially each vector is a different basis vector at this point
- This eventually results in the common curse of dimensionality issue where data becomes too sparse and models stop learning / updating
- Having these sparse, orthogonal vectors means you cannot generalize easily
- There's no good way to generally compare words for similarities, as you cannot comapare
[1,0]to[0,1]in a general fashion over millions of vectors
- There's no good way to generally compare words for similarities, as you cannot comapare
Therefore, these sorts of categorical embeddings can be made better by use of dense embeddings over a smaller overall dimensional space (i.e. less dimensions, with more information "squished" into each dimension)
From this, word embeddings ultimately moved towards dense representations of floating point numbers, known as Text Embeddings where the dimensionality of embeddings is typically much smaller than the number of words in the dictionary which allows for space reduction, information gain, and geometric comparisons
Numeric Features
- Standardization: Transforms the data to having a mean of zero, and a standard deviation of one
- This allows us to bring data in different distributions onto the same common scale
- Normalization: Brings the data to a specific range between
- This is helpful when you want to ensure all features contribute equally to the model
- When to use what?
- Standardization:
- Use when the features have different units or scales
- Useful for algorithms that assume the data is normally distributed (e.g., linear regression, logistic regression, SVM)
- Helps in dealing with outliers.
- Normalization:
- Use when you want to scale the data to a specific range (e.g., [0, 1])
- Useful for algorithms that do not assume any specific distribution of the data (e.g., k-nearest neighbors, neural networks)
- Ensures that all features contribute equally to the model
- Standardization:
- There are plenty of other ways to treat numeric data as features, but not covering them here
Text Embeddings
Text Embeddings are one of the harder things to figure out, but there are some standards nowadays
Text embeddings can be seen as a static form of transfer learning, where models will create static word embeddings and over time anyone can re-use these via a lookup object for any word - the word "bank" in terms of river bank, or financial institution, will have the same embedding here
- Training Word2Vec and BERT both involved semi self-supervised training where they take online corpus as input and basically use contextual words to try and create an embedding for a current word
- Word2Vec was one of the original ideas for text embeddings - it essentially acts as an autoencoder to create static embeddings for each word in a dictionary
- BERT on the other hand, through attention, can create contextual embeddings for words, sentences, and entire documents
- GPT is an autoregressive transformer model in the same transformer "family" as BERT, but it is unidirectional where BERT is bidirectional (which is constantly repeated in the paper)
- GPT is good for text-to-text tasks like question answering, but like BERT you can pull from the middle hidden layers during it's self-attention steps to find word embeddings
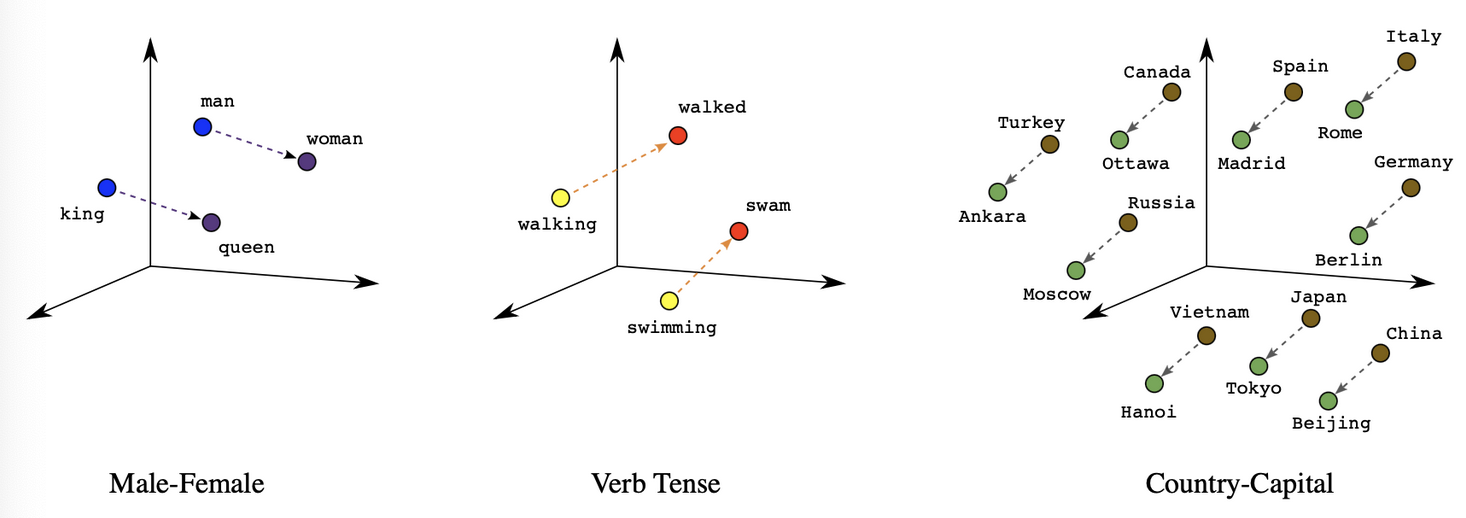
Word Embeddings made it possible and allowed developers to encode words as dense vectors that capture underlying semantic content - King - Man + Woman = Queen. Similar words were embedded close to each other in lower dimensional feature spaces, and allowed for geometrical operations.
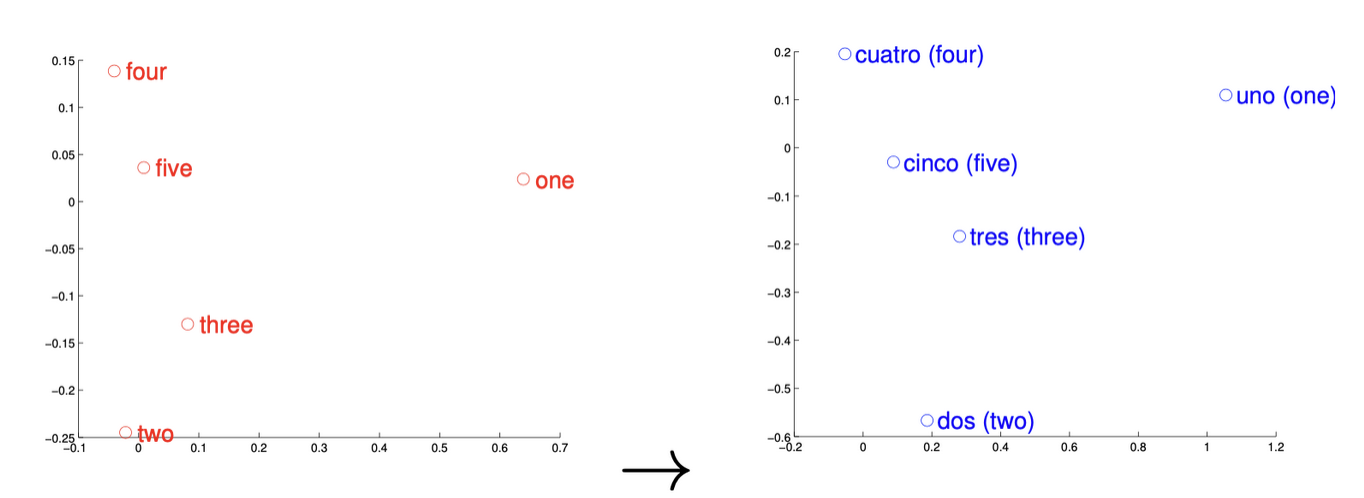
These examples have even been shown to hold across languages, where youc can map One Uno - this ultimately showed 90% precision across words, and showcases that some languages may have an isomoprhic (one-to-one and onto) topological mapping for some % of their words. Other languages like English Vietnamese has a much lower overlap, showcasing a relatively small one-to-one correspondence because the concept of a word and meanings of them are vastly different in the 2 languages. I still think this is one of the more interesting case studies; Other groups took this further and removed words from the vocabulary and retrained the models and were able to find "missing vectors" of the vocabulary words they had taken out that were "missing" in the one-to-one translation
Word2Vec
Word2Vec is a family of algorithms and techniques to create static embeddings
It will create dense embeddings for all words, subwords, or tokens in vocabulary, and then they can be used in the future for many downstream tasks - if you have static embeddings for all words in a sentence, you can average / add / min-max or something else to create a sentence embedding. These embeddings are static though, so the embedding for bank is the same regardless of if it refers to a river bank or a financial institution
- Parameters:
- is context window size (input size)
- is the number of words in our dictionary
- is the embedding size (projection layer)
- is the current target word
Training and Output
Word2Vec is shallow 2 layer NN trained on a vocabulary of texts and tokens. Typically words are tokenized out into sub-words which ultimately reduces the total size of the corpus. #ing is a common token, which can be paired with cook, read, fish, etc instead of duplicating all of those words in different contexts
The training architecture is meant to update middle hidden layers of word representations by altering them in geometric space so that downstream objectives lower their loss, and in doing this eventually the middle hidden layers will actually just become the token embeddings themselves, and we can trash the later layers. These hidden layers are updated by multiple objectives like CBOW, Skip-Gram, and other methods in the Word2Vec family, and the sampling, objectives, and architecture tweaks help to optimize the total runtime of the model and prevent overfitting
Training hidden layers with different objectives, and then utilizing those hidden layers as embeddings, is a common practice in semi-supervised learning. There is no exact output for each input word, but you can create actuals via context and surrounding words. Many other areas of self semi-supervised learning are grouped into this - autoencoders will try and reduce dimensionality and compress objects by producing an encoding hidden layer, and contrastive learning is an objective where you augment inputs and try and predict the original and augmented pairing - you can use transformations, context, etc to generate pairs to update model weights on, without having explicit labeled training data
Model Architecture and Optimizations
Word2Vec has a similar architecture to an autoencoder where you take a large input vector, compress it down to a smaller dense vector, and then instead of decompressing it back to the original input vector (which is what's done with autoencoders), W2V outputs probabilities of target words
Inputs to W2V are one-hot encoded vectors, because you have to start somewhere with some sort of input. The hidden layer is a standard fully-connected (dense) layer, and the output layer consists of probabilities for target words from the vocabulary
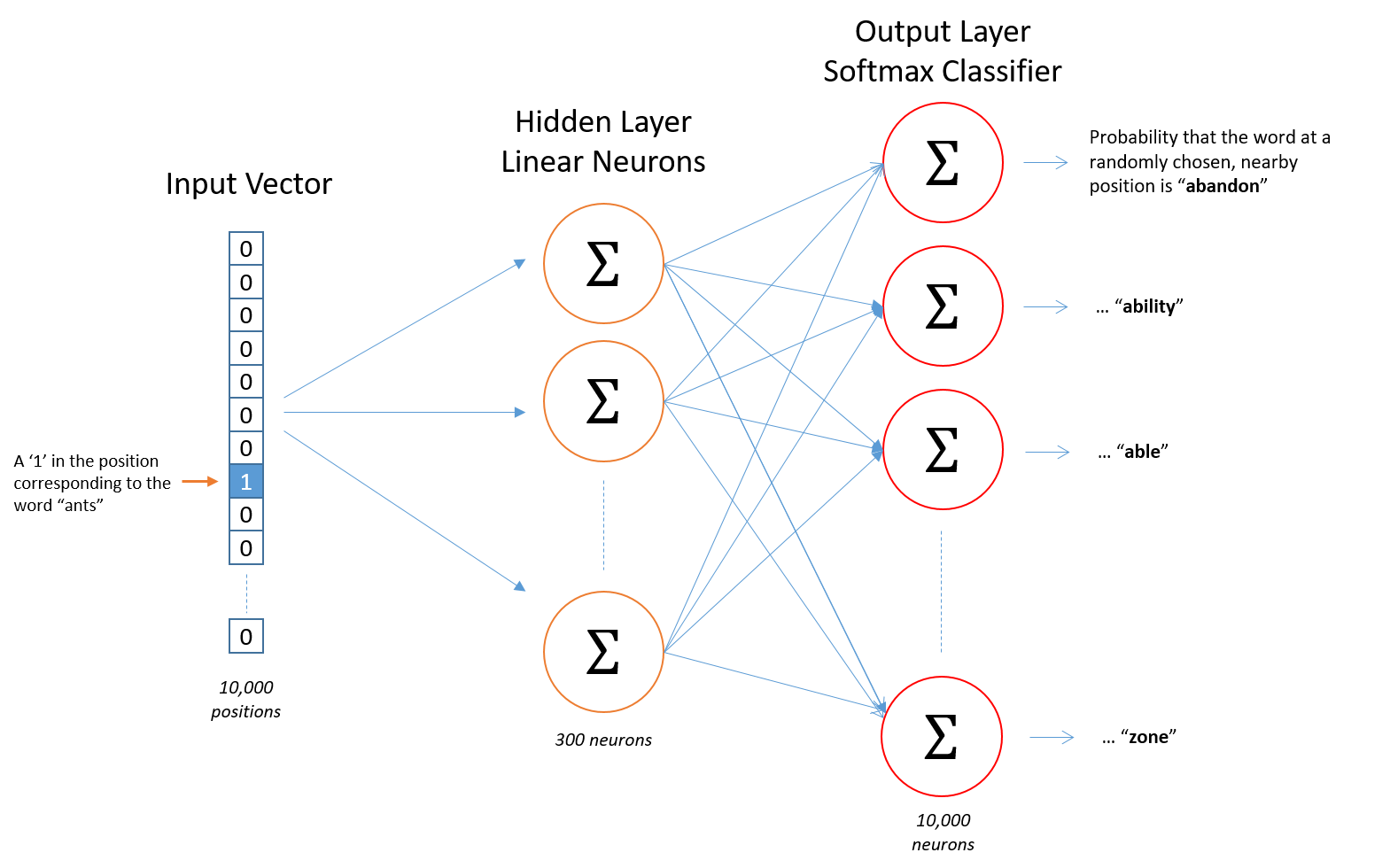
For the CBOW architecture, we take input context words and produce a singular output representing our predicted current word:
- Input Layer:
- One-hot encoded vectors representing the word
- If our vocabulary is size , the dimension of the input would also be , and the input is a sparse vector of all 0's and a single 1
-
- examples will come in via context words
- For each of these context words, we will need a one-hot encoded vector of size
- Hidden Embedding Layer:
-
- Will need to transform the layer via fully connected dense transformations into our lower dimensional embedding layer
- The output will be where we have a weighted row for each of the inputs

-
- Output Layer:
- General purpose usually consists of softmax classifiers
- input from hidden layer will be output to
- Basically, the output is a single vector of size with probabilities assigned to each word
For each input word we'll multiply it by the current representation embedding, so in the below ants and cars example the input hidden embedding multiplication can be interpreted as "how similar is ants vector to cars vector"

If ants and cars are similar, then this resulting output will be larger and will influence softmax to choose cars instead of another word. Most likely ants will be closest with a word like insect or bug, and softmax loss function will update the weights to become closer to those representations over each backwards update to weights
Optimizations
To run the actual above technique is computationally expensive, as you'd need to compute and normalize all vocabulary words at each training step which isn't necessary. Negative sampling and hierarchical softmax allow us to update words and compute outputs for only a small set of context words and "other words" which makes this much more feasible at a larger scale - you don't need to update the embedding for "Mexico" for the input word "chair" (most likely), and so negative sampling, hierarchical softmax, etc all revolve around those optimizations
- Hierarchical Softmax uses a Huffman Tree to reduce overall calculation by approximating the conditional log-likelihood at the ending softmax classification layer
- Huffman tree's help us to get to utilizing memory complexity instead of full that would be needed for comparing every vocabulary word to every other one
- As training epochs increase, hierarchical softmax stops being useful
- TODO write more in softmax area on loss and link here
- Negative Sampling samples negative instances along with the actual target word inside of the total context . Negative sampling helps to ignore most of the "0" in the one-hot encoded vectors and resulting vocabulary, and so we only have to propogate weight updates to instances instead of the entire vocabulary during each backwards pass
- Negative sampling samples negative instances (words / tokens) along with the target word and minimizes the log-likelihood of the sampled negative instances while maximizing the log-likelihood of the target word
- Negative samples are typically chosen using a unigram distribution, which intuitively means the probability for selecting a word as a negative sample is related to it's frequency. More frequent words are more likely to be sampled as negatives
- Each word is given a weight equal to it's frequency (word count) raised to the #3 \over 4$ power, and then the probability of any word is it's weight divided by the sum of weights for all words
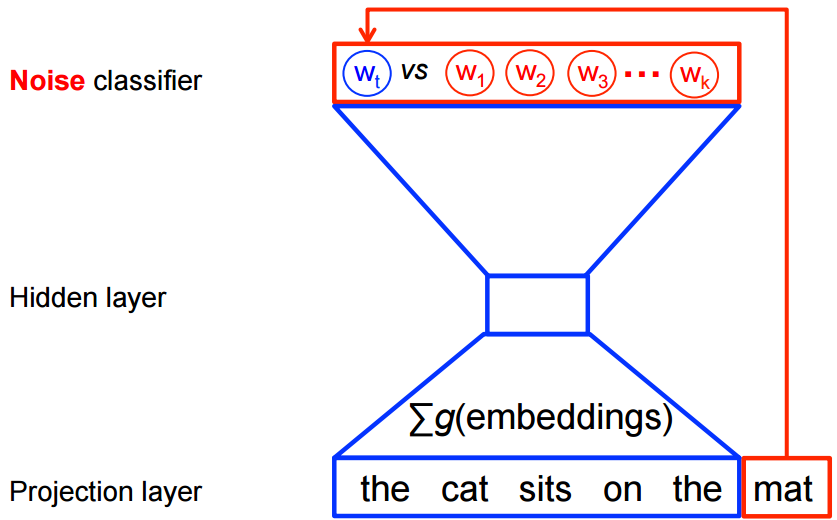
- Sub Sampling is a technique to avoid calculating extremely frequent words / tokens such as it, is, a, the, etc..
- These more frequent words won't provide much more information, and so ideally they are skipped over more often during training to speed up the process
- Words above a certain threshold can be sub-sampled to increase training speed and performance
- Curse of Dimensionality comes up as larger dimensional vectors will produce better embeddings up to a certain threshold, where afterwards the quality starts to rapidly diminish in terms of quality increase per dimension increase
- Typically the dimensions are set between 100 and 1,000
The hidden layer is size , because we'll need to represent all words with some potential weight matrix
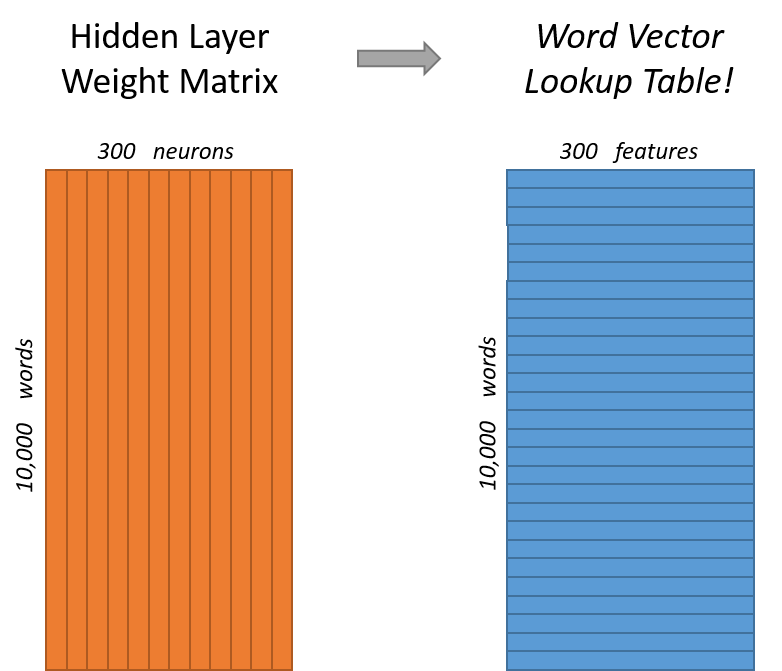
Continuous Bag of Words Architecture
The CBOW architecture will use some surrounding context of words, , to predict the current word
- The context words get projected into hidden layer, and then they are basically all averaged
- This means there is no context involved, and that the surrounding words are simply averaged
- For the context words, past and future words are used
- In the paper with 4 before (historic), and 4 after (future)
- Training Objective: Predict the middle word from the surrounding context words
- Time Complexity: Would be
- General rule of thumb: Pluses separate layers, multiplication shows layer dimensions / work
- The output layer is a
log-linear classifier- TODO: Explain log-linear classification
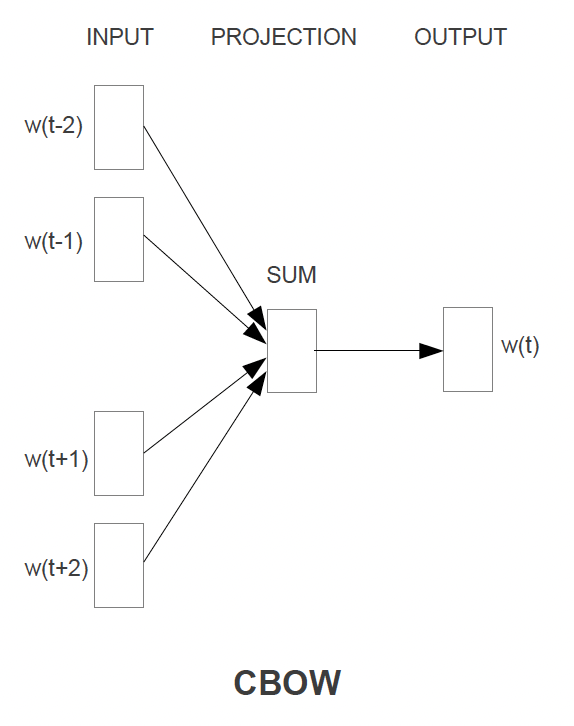
Continuous Skip Gram Architecture
The Skip Gram architecture will use the current word as input to predict each one of the context words
- The current word is sent through a
log-linear classifierinto a continuous projection layer, and then they projection layer is used to predict the best potential context words- This still! means there is no context involved, and that the surrounding words are simply predicted without specifying placement
- Training Objective: Predict some surrounding context words from the current word, and then pick, randomly, words from the context words
- Since more distant words are most likely more unrelated to the current word, you reduce computational complexity by sampling from those words less frequently
- There's no other way to give less weight to other "far away" words other than sampling them less and updating weights less often based on them
- Time Complexity: Would be
- For each of the words you need to take our input word , do multiplcations to get it into projection layer, and then go from our projection layer into our sized vocabulary to try and predict
Evaluation of Model
Evaluating an embedding model is a subjective process over each evaluation objective - do you want to check words having a 1:1 mapping over languages, or check for semantic similarity, or even something else like word clustering. Each objective function needs to have evaluation datasets, and
-
In the past the main way to do this was to just show tables of words with their corresponding Top-K most similar other words, and intuitively check
-
In the Word2Vec Paper they checked over relationships such as "What is the word that is similar to small in the same sense as bigger is to big"
- Ideally this would produce smaller
-
This can be done with algebraic operations!
vector(big) - vector(bigger) + vector(small)would give us that sort of output, and then you just find the closest vector via Cosine Distance -
There are other relationships to test such as France is to Paris as Germany is to Berlin
-
Skip Gram performed better on semantic objectives, which isn't surprising seeing as it's entirely focused on structuring a word to best represent what other words would be around it, so
AmericaandUnited Statesshould be similar- Skip-gram also typically performs better on larger datasets, and continuously has the highest accuracy metrics on most datasets
-
Bag of Words performed better on syntactic objectives showing how the CBOW model is better at syntax modeling where you could alter the sentence The quick brown fox jumped over the lazy river to Over the lazy river the quick brown fox had jumped
- CBOW produces similar, but worse, accuracy metrics compared to skip-gram, but is much more computationally efficient
Encoder Decoder
Encoder-Decoder frameworks are explained more in Seq2Seq
These frameworks helped to setup underlying generative language models, and the section used to live here but ultimately is a different fundamental area. Encoder only models, like BERT, are extremely good at creating embeddings, and most encoder-decoder models like T5 are able to create embeddings, but are better suited at generative language tasks
BERT
BERT architecture, training, and fine tuning is descirbed in another page, but given all of that is read through you discuss below how to get useful embeddings out of BERT!
BERT uses encoder architecture above along with attention
Since BERT is an Encoder Only Model, it basically takes an input, runs it through multiple Encoders, and would send it through an output layer at the end - this output layer tyipcally isn't useful by itself for Word Embeddings, so you would need to go back through the hidden state values and aggregate these in some way to produce Word, Sentence, or Document embeddings
BERT Word Embeddings
- Another reference link
- Most use cases of word embeddings can come straight out of a pre-trained core BERT model
- You could send a single word through and it would most likely just be a representation of the WordPiece Embedding layer at the start
- If you send multiple words through (a sentence) then you could try and reconstruct each individual words new embedding that was altered from the self-attention layers
bankin the sentencethe large and sandy river bankwill be attended to, and ultimately different, fromthe countries central bankbecause it's surrounding context words are different!- Typically you would send through the sentence and then pull back each , or some mixture of hidden states, for each and that would represent your finalized word embedding that was attended to / altered from contextual self-attention!
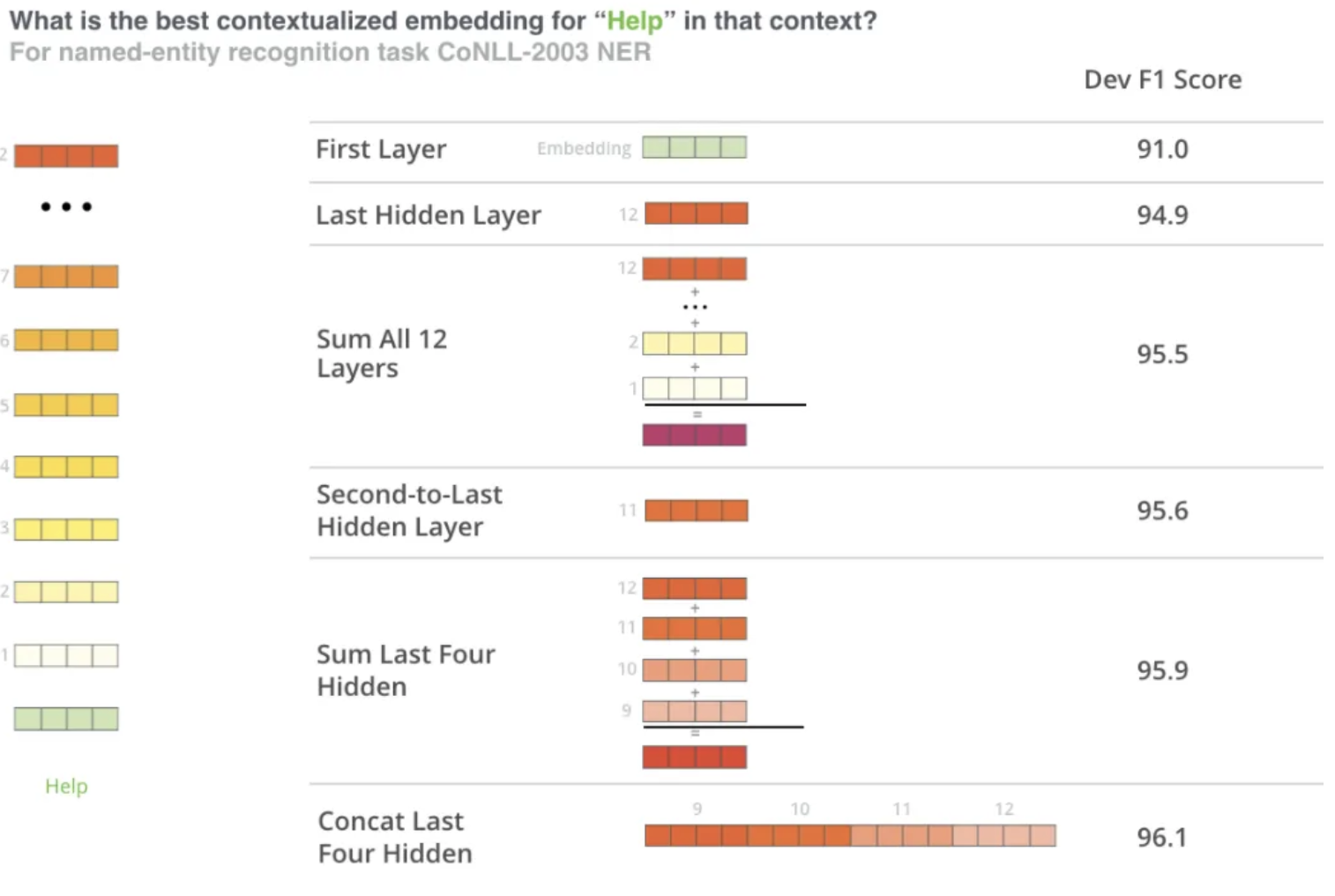
BERT Embeddings Pseudo Code
- We'd need to load in the WordPiece Tokenizer
- Tokenize our sentence input into Word Pieces
- Will have some words get split into tokens like
embeddings -> [em, ###bed, ###ding, ###s]
- Will have some words get split into tokens like
- Load the pre-trained BERT model
- Set the model to
eval()mode since you do not want to go through updating the base models weights for inference time
- Set the model to
- Get the token ID's for each of these tokens from the pre-trained BERT state file
- Create a segement embedding (can just be repeated 0's and 1's of same size as token embeddings) which represent what sentence these tokens are apart of
- In this scenario to embed one sentence you will most likely just have all 0's in our segment embedding
- Pass the token and segment tensors through the BERT model
- It will output all of it's hidden layers - these include multiple dimensions:
- The layer number (13 layers)
- Input WordPiece embedding + 12 hidden layers
- The batch number (1 sentence)
- Used to batch together multiple sentences for inference, for now it's just 1
- The word / token number (22 tokens in our sentence)
- The hidden unit / feature number (768 features)
- The layer number (13 layers)
- Most people permute this output to get it in the order of
[# tokens, # layers, # features]- From this you have 13 separate vectors of size 768 for each token
- Once this is done you can just directly
SUM,CONCAT,AVG, etc...some mixture of hidden layers together to get our final word embedding - TODO: Why do the hidden states represent the word embeddings? These don't get updated for our words right? If you model an entire corpus why would sending
0, 1000, 4500through as a list of token ID's give us any sort of information? If I send through0, 1001, 4500are things that different even though I might be discussing a completely different word? - TODO: What do the hidden layers of a BERT model represent? They're optimized parameters for language modeling...how does that relate to word embeddings?
Why does this work?
- The embeddings start out in the first layer with 0 contextual representation in them -
river bankandcentral bankare the samebankembedding - As the embeddings move deeper and deeper into the network they pick up more contextual information
- As you approach the final layer you start to pick up information about the pre-trained BERTs tasks, MLM and NSP respectively
- BERT is setup well to encode information, but at the end of the day BERT is meant to predict missing words or next sentences
BERT Sentence Embeddings
- Taking the above example, the typical way to get sentence embeddings is to
SUMorAVGthe second to last hidden state for each token in the sentence to achieve a sentence embedding
User Embeddings
TODO: Outside of collab filtering, how do you get user embeddings? TLDR; How do you get meaningful representations of users?
Embeddings vs Autoencoder vs Variational Autoencoder
This question has come up in my own thoughts, and others have asked me - they all get to a relatively similar output of representing things into a compressed numeric format, but they all have different training objectives, use cases, and architectures - Autoencoders were created to reduce dimensionality, and Embeddings were created to represent, possibly dense items, into dense numeric representations
Embeddings
Description
- Embeddings are dense vector representations of objects (e.g., words, users, items) that capture their semantic or contextual meaning in a continuous vector space
- They are typically learned during the training of a neural network and can be static (pre-trained) or dynamic (contextual)
Use Cases
- Static Embeddings:
- Pre-trained embeddings like Word2Vec or GloVe are used for tasks where the context does not change (e.g., word similarity tasks)
- Example: Representing the word "bank" as a fixed vector regardless of its context
- Dynamic Embeddings:
- Contextual embeddings like BERT or GPT are used for tasks where the meaning of the object depends on its context
- Example: Representing "bank" differently in "river bank" vs. "central bank."
When to Use
- Use embeddings when you need a lightweight, efficient representation of objects for tasks like:
- Search and retrieval (e.g., cosine similarity between query and document embeddings)
- Recommendation systems (e.g., user-item embeddings)
- Pre-trained embeddings for transfer learning
Autoencoder
Description
- An Autoencoder is a type of neural network designed for dimensionality reduction. It learns to encode input data into a compressed representation (embedding) in the hidden layer and then reconstructs the original input from this representation
- It's typically used to represent sparse data into a more compact format
- The encoder compresses the input, and the decoder reconstructs it
- So what's the difference between an Autoencoder and Word2Vec?
- Word2Vec doesn't get train input word to be reconstructed on the other side (outright) like an Autoencoder, instead it tries to predict surrounding words...therefore the end results are ultimately the same, but the training tasks are different
Use Cases
- Dimensionality Reduction:
- Reducing high-dimensional data into a lower-dimensional embedding while preserving important features
- Example: Compressing image data for visualization or clustering
- Static Embeddings:
- The hidden layer of the Autoencoder can be used as a static embedding for the input data
- Example: Representing user profiles or item features in a recommendation system
When to Use
- Use Autoencoders when:
- You need static embeddings for structured data (e.g., tabular data, images)
- The input and output are the same, and you want to reduce dimensionality
- You do not need to generate new data points but only want a dense representation of existing data
Variational Autoencoder (VAE)
Description
- A Variational Autoencoder is an extension of the Autoencoder that introduces a probabilistic approach. Instead of encoding the input into a single deterministic vector, it encodes it into a distribution (mean and variance)
- The decoder samples from this distribution to reconstruct the input, allowing the generation of new data points
Use Cases
- Generative Models:
- VAEs are used to generate new data points similar to the training data
- Example: Generating new images, text, or user profiles
- Dynamic Embeddings:
- The latent space of the VAE can be used to create embeddings that capture uncertainty or variability in the data
- Example: Representing user preferences with variability for personalized recommendations
When to Use
- Use VAEs when:
- You need to generate new data points (e.g., synthetic data generation, data augmentation)
- You want embeddings that capture uncertainty or variability in the data
- The task involves probabilistic modeling (e.g., anomaly detection, generative tasks)
Comparison and When to Choose
| Technique | Static Embeddings | Dynamic Embeddings | Generative Tasks | Dimensionality Reduction |
|---|---|---|---|---|
| Embeddings | Yes | Yes | No | No |
| Autoencoder | Yes | No | No | Yes |
| Variational Autoencoder (VAE) | No | Yes | Yes | Yes |
| Word2Vec | Yes | No | No | No |
Key Considerations
-
Static vs. Dynamic Embeddings:
- Use Autoencoders or Word2Vec for static representations
- Use BERT or some sort of Transformer model with Attention for dynamic embeddings
-
Dimensionality Reduction:
- Use Autoencoders or VAEs when you need to reduce the dimensionality of high-dimensional data
-
Generative Tasks:
- Use VAEs when you need to generate new data points or capture variability in the data
-
Lightweight Models:
- Use Word2Vec for lightweight, static word embeddings
Vector Similarities + Lookup
Vector similarities are useful for comparing our final embeddings to others in search space
None of the below are actually useful in real life, as computing these for Top K is very inefficient - approximate Top K algorithms like Branch-and-Bound, Locality Sensitive Hashing, and FAISS clustering are used instead
Quantization
Quantization
- Definition: Quantization is a technique used to reduce the size of vector representations (e.g., embeddings) while preserving their ability to compare similarity effectively
- How It Works:
- It reduces the precision of the numerical values in the vector (e.g., from 32-bit floating-point to 8-bit integers)
- This compression reduces memory usage and speeds up computations, especially for large-scale systems.
- Key Idea:
- The goal is to maintain the relative distances or similarities between vectors in the embedding space, even after reducing their size
- Use Cases:
- Approximate Nearest Neighbor Search: Quantized vectors are often used in libraries like FAISS to perform fast similarity searches
- Edge Devices: Quantization is used to deploy machine learning models on devices with limited memory and computational power (e.g., mobile phones, IoT devices)
- Limitations:
- Quantization introduces some loss of precision, which can slightly affect the accuracy of similarity comparisons
Sketching
TODO:
Feature Multiplexing
TODO:
Cosine
Cosine similarity will ultimately find the angle between 2 vectors
- Where
- is the dot product of vectors and .
- and are the magnitudes (or Euclidean norms) of vectors and
- Therefore, magnitude has no effect on our measurement, and you only check angle between vectors
- Cosine similarity ranges from where:
- 1 indicates they're overlapping and pointing in the exact same direction
- 0 indicates they're fully orthonormal (right angle) with 0 overlap over any dimensions
- -1 indicates they're pointing in exactly opposite directions
Dot
The Dot product is similar to the Cosine product, except it doens't ignore the magnitude
Which basically means you just compare each item over each dimension. If are normalized then Dot is equivalent to Cosine
Euclidean
This is the typical distance in euclidean space
Here magnitude matters, and a smaller distance between vector end-points means a smaller overall distance metric
Topological Interpretations
Most of this comes from Yuan Meng Embeddings Post
There you see discussions of how embeddings, topologically, can be considered a injective one-to-one mapping that preserves properties of both metric spaces
you can also see that from a ML lense, embeddings represent dense numeric features in n-dimensional space
- Images can go to
3 colors x 256 pixelsdimension using photo represenation on disk (this is just how photos are stored) - Text can go from sentences to
256 dimensionvectors in Word2Vec or BERT - Text can go from address sentences to
[lat, long]2 dimensions - you cover this in Address Embeddings
The main point of all of this is that Embeddings equate to → topological properties are preserved - that's what allows the famous King - man + woman = Queen and France is to Paris as Germany is to Berlin
A random list of numbers is a numeric representation, but they are not Embeddings
One-hot encoding, kindof, preserves topolological properties, but all of the vectors end up being orthogonal to each other so you can't say category1 + category2 = 0.5category3...they're orthogonal! Typically you need to map these from OHE metric space to a lower dimensional metric space to get those properties out of it
Dual Encoder
Much of the discussion below this point stems from this Multimodal Blog
Dual encoders have a number of different use cases and interpretations - there's using multiple encoders that end up in similar embedding spaces so you can do comparisons - this is helpful in RAG or query-document comparisons
There are other encoder architectures that focus on different modalities so that you can compare text to images to audio
At the end of the day, all of these architectures are designed so you can do dot-product similarity searches in an embedding space
Query Document Retrieval
A dual encoder consists of two separate neural networks that encode two different sets of data into their respective embeddings
For example:
- RAG Uses a query encoder and a document encoder
- Question Answer Uses a question encoder and an answer encoder
- There are other comparisons like caption and image, audio and language classification, or image to OCR
At the end of all of these, the two inputs are transformed into embedding space(s) which allow us to do similarity searches to find ANN's
Two Tower Architecture
During training in something like Question-Answer, you would encode each of them separately and then train to maximize the similarity between the two, and minimize the similarity between others
This can utilize a Contrastive Learning approach if there's a way to create augmentions, or if you use n-pair loss, or simply using Cross-Entropy Loss over entire dataset can work too
In examples online it mostly utilizes Cross-Entropy Loss over entire answer dataset
Two Towers is useful so you can pre-compute candidates and do fast ANN lookup during inference. It also helps solve some modality issues, but that's also covered later in Fusion
During Inference and Serving, all you have to do is calculate embedding for an incoming query and it allows us to quickly find ANN neighbors in an index and return the top K to the client. All document embeddings can be pre-computed, so you only have 1/2 of compute need during inference
- Run a batch prediction job with a trained candidate tower to precompute embedding vectors for all candidates, attach NVIDIA GPU to accelerate computation
- Compress precomputed candidate embeddings to an ANN index optimized for low-latency retrieval; deploy index to an endpoint for serving
- Deploy trained query tower to an endpoint for converting queries to embeddings in real time, attach NVIDIA GPU to accelerate computation
Google came up with a novel compression algorithm that allows for better relevance, and faster speed, of retrievals which is known as ScaNN. This service is then fully managed by Google Vertex AI Matching Engine
- Distributed search tree for hierarchically organizing the embedding space. Each level of this tree is a clustering of the nodes at the next level down, where the final leaf-level is a clustering of our candidate embedding vectors
- Asymmetric hashing (AH) for fast dot product approximation algorithm used to score similarity between a query vector and the search tree nodes
These architectures also allow us to address cold start problems since you can put through user features or generic default features to pull popular candidates
Multimodal Retrieval
Multimodal retrieval can be viewed as a specific implementation of Two Tower, where towers have different modalities - one may be a text query, and the candidates may be audio tracks
you can also use Fusion in our towers here so that whether it's a text or audio input you can use it and compare to image candidates for ANN lookup
Image2Text
This model focuses on image captioning or overall providing descriptive text for given images
It was one of the initial approaches to multi modality focusing on NLP and CV architectures that were combined into a shared embedding space
Microsofts Common Objects in Context (MS COCO) was a foundational dataset for this - it focuses on detecting non-iconic views, detecting semantic relationships between objects, and determining the precise localization of objects. It contained 91 common object categories with 328,000 images and 2.5 Million instance labels
Some Transformer architectures were used where the transformer consists of an encoder with a stack of self-attention and feed-forward layers, and a decoder which uses (masked) self-attention on words and cross-attention over the output of the last encoder layer
Ultimately it's a way for us to use Vision Transformers and Lanugage Encoders in the same model - one of the more useful examples was the Meshed-Memory Transformer for Image Captioning. The input was a photo with bounding boxes, and the image would get chunked out into a sequence and encoded with full self-attention. At the end each encoding layer output is fed into each decoder layer in a mesh-style relationship between the two layers
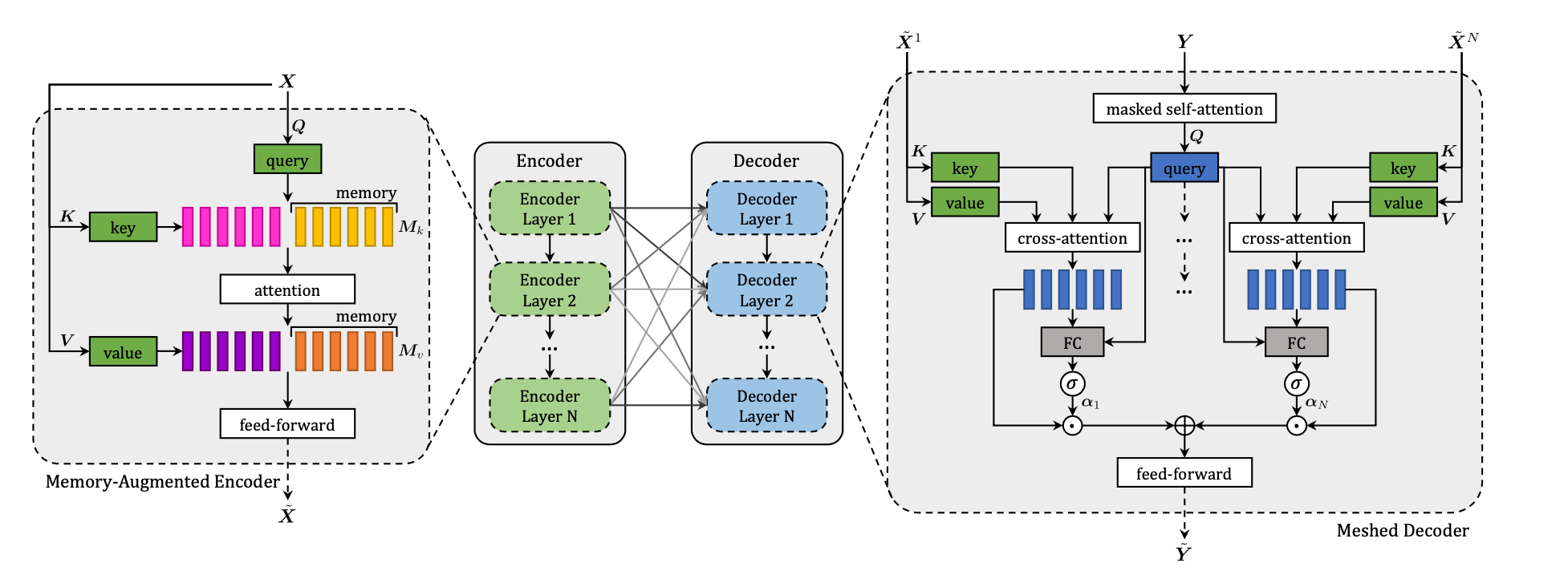
CLIP
Contrastive Language Image Pretraining (CLIP) is a transformer like architecture that jointly pre-trains a text encoder and an image encoder at the same time using Contrastive Learning
The contrastive goal is to correctly predict which natural language text pertains to which image inside a certain batch - this turned out to be more efficient than training on captions of images
Introduction to Fusion
Fusion involves combining multiple modalities into single models / architectures to aid in multimodal retrieval
It allows us to bypass model-per-modality - while this sounds like it can rid of two towers that's beside the point. Two Towers is useful so you can pre-compute candidates and do fast ANN lookup during inference
How to integrate multiple modalities? On one side of the spectrum, textual elements and visual ones are learned separately and then “combined” afterwards (left), whereas on the other side, the learning of textual and visual features takes place simultaneously/jointly (right)

The ultimate goal, that seems to have been achieved, is to move away from model-per-modality and focus on robust foundational models that can incorporate all types of modalities while allowing them to attend to each other
Some of the earliest movers were Data2Vec, Flamingo, and Vilbert - Data2Vec, for example, was to predict latent representations of full input data based on a masked view of the input in a self distillation step. you can see the parallels here between Transformers, Contrastive Learning, and Multimodality