NLP, CV, and Transformers
NLP
Note: A large portion of this references the SLDS Blog
Over the last 50+ years NLP has existed, but in the last decade or so NLP has taken off with many breakthroughs including Word Embeddings, LSTM, Seq2Seq, Transformers, Attention, Generative Models, and more
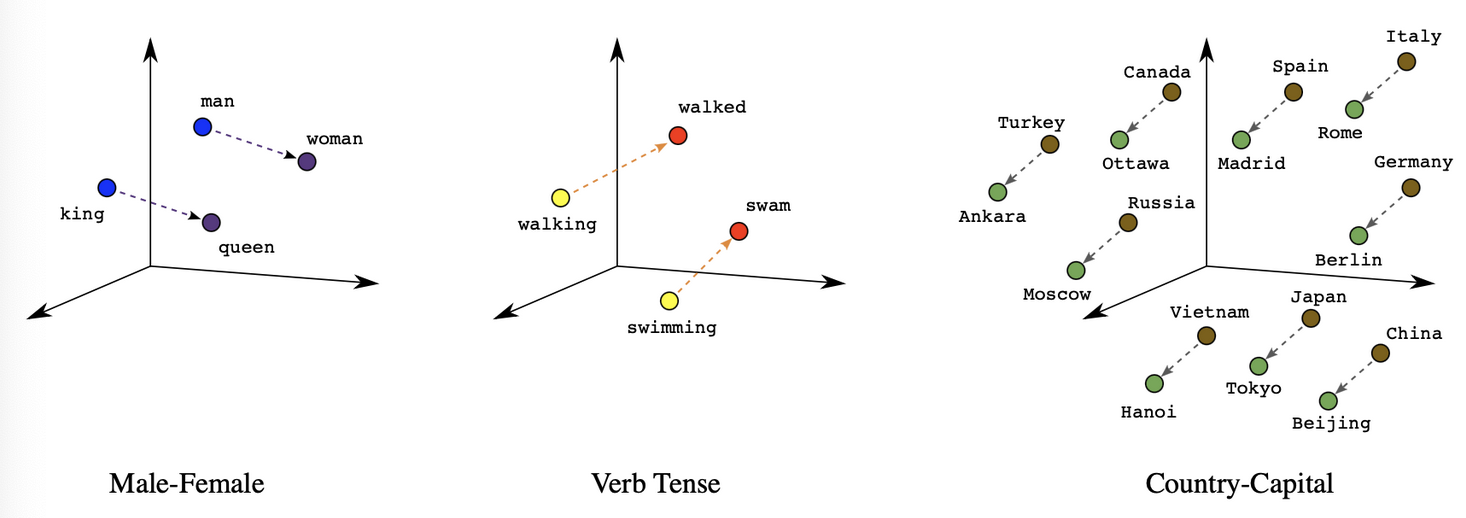
Word Embeddings made it possible and allowed developers to encode words as dense vectors that capture underlying semantic content - King - Man + Woman = Queen. Similar words were embedded close to each other in lower dimensional feature spaces, and allowed for geometrical operations.
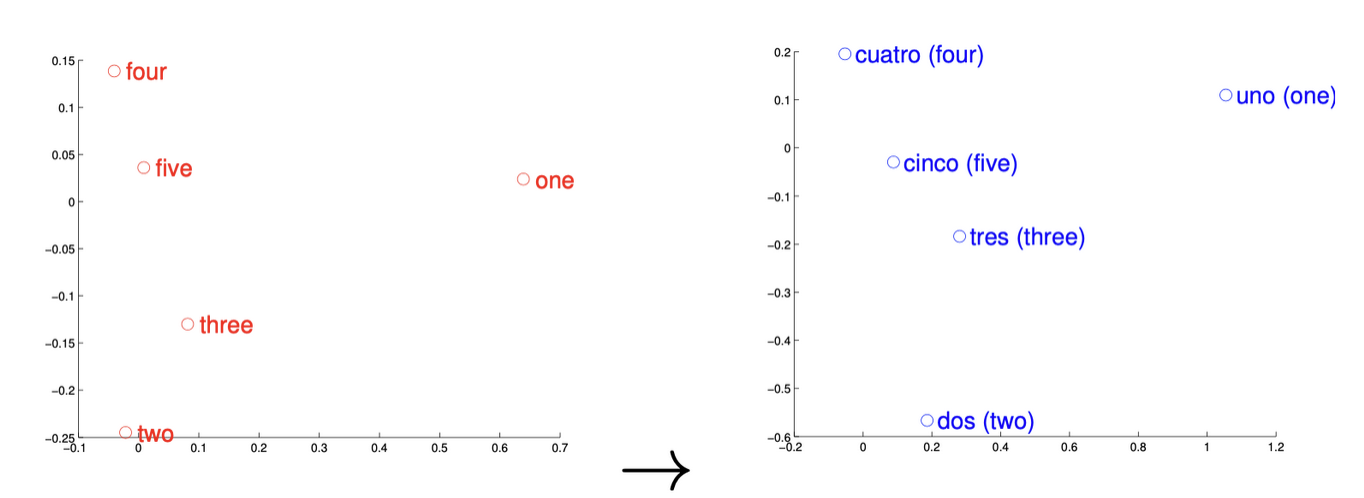
These examples have even been shown to hold across languages, where youc can map One Uno - this ultimately showed 90% precision across words, and showcases that some languages may have an isomoprhic (one-to-one and onto) topological mapping for some % of their words. Other languages like English Vietnamese has a much lower overlap, showcasing a relatively small one-to-one correspondence because the concept of a word and meanings of them are vastly different in the 2 languages.
Encoder-Decoder (Seq2Seq) made it possible to map input sequences to output sequences of different lengths, because "I want a coffee with milk" and "Yo quiero cafe con leche" have different total lengths of words (even if it's just "a"). This also allowed for taking in entire photos, and outputting a text representation (video captioning), outputting bounding box anchors of objects (object detection), and many other future architectures.
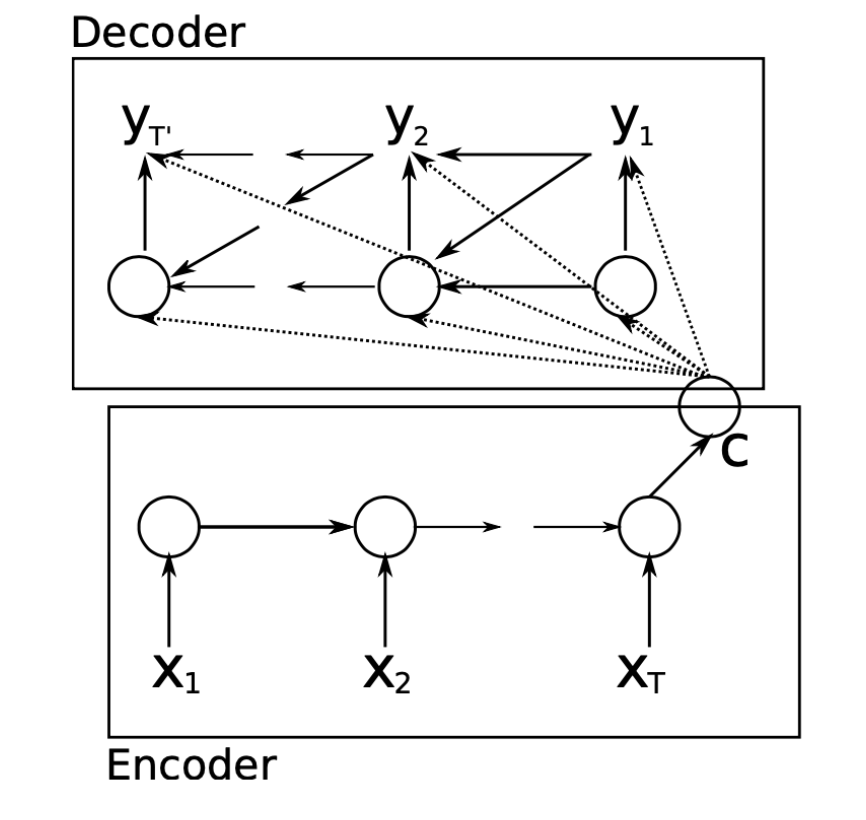
Attention enabled models to actively shift their "focus" depending on different words in different locations. "The bank teller was weak" and "The river bank was weak" are almost identical sentences with 2 completely different meanings. It also allowed for decoders to directly see the source sequence that was encoded, which meant state didn't have to get passed around like in RNN's - the bottleneck of "state" was removed, and thus helped with the vanishing gradient problem. Attention also helps to alleviate the bottleneck problem, where all context is "shoved" into a singular vector. Attention allows all encoded infromation to help influence the context and decoding during each step, and helps to alleviate the vanishing gradient problem from long sentences that end up multiplying multiple numbers 1.0 throughout numerous steps.
"You shall know a word by the company it keeps", an adage by linguist John Rupert Firth from 1957 goes. Even earlier, in 1935, he stated that "... the complete meaning of a word is always contextual, and no study of meaning apart from a complete context can be taken seriously"

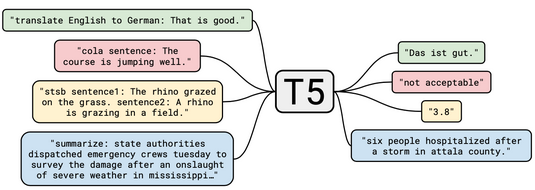
Transformers were born from attention, and do not have to process input data sequentially like RNN's. Currently this is still the dominant paradigm in NLP, and greatly increased the demand for GPU's as a majority of their calculations can be done in parallel. Transformer Architectures like BERT), T5, GPT, and BART are pre-trained on a large text corpus and then can be fine-tuned for down stream specific language tasks. One of the most useful topics is getting more data without human supervision, and this is the core topic of Contrastive Learning which has helped these models greatly improve accuracy and reliability
Outside of BERT, there are other models like T5 (Text-To-Text Transfer Transformer) which takes a number of insights from emperical studies to create a model fit for transfer learning as a whole. It was trained on the Colossal Clean Crawled Corpus (C4). It's best fit objective was span corruption, which is when different length word groups (spans) are replaced with unique placeholders, and the model tries to decode them. However, the decoder is still a language modelling task. T5 allows for unified text-to-text format for transfer learning for all NLP tasks where all inputs and outputs consist of text strings - this means the model, the same weights, hyperparams, etc, can be used for all NLP tasks. So while not multi-model, T5 was the first "single model multi-task" by simply viewing all inputs and outputs as strings - even regression tasks it can output "0.5"!
BERT can be seen as stacked encoders, T5 aims to combine the good parts of encoders and decoders, while GPT are stacked decoders
GPT-3 takes things to the next level - While the largest T5 model has 11 billion parameters, GPT-3 has 175 billion parameters. Moreover, the training data set contains around 500 billion tokens of text, while the average young american child hears around 6 million words per year. The results of huge language models suggest that they perform some form of learning (without gradient steps) simply from examples provided via context. The tasks are specified by the in-context examples, and the conditional probability distribution simulates performing the task to an extent. GPT's also view things as "text-to-text", and with the sheer volume of parameters, examples, and data they've shown great abilities of emergent tasks that they weren't specifically trained for.
Few Shot Learning helps us to have to avoid costsly human annotations (to some extent) - few shot learning defines a model that is trained on a limited number of demonstrations to guide it's predictions. Zero and One shot learning refer to model predicitng with no, and one, learned examples respectively. Few shot applications differ because they have to complete tasks at test time with only forward passes. They are made up of 3 main parts:
- Task description: What should the model try to achieve
- Examples: Some examples of the task and it's inputs and outcomes
- Prompt: Some form of input to the task description

Few shot performance scales with the number of model parameters, so GPT-3 naturally outperformed other models at this, but was still susceptible to issues with how training examples, decoding strategies, and hyperparameter selections were done.
Reinforcement Learning is becoming another dominant paradigm, but it's typically used to train and refine models in a Transformer Architecture, and is a helpful boost instead of a direct replacement
Overall, NLP is a gigantic mega-field in ML applications, and possibly the most used modality because of the internet's web traffic being written in text format. Word Embeddings started everything off, where similar words were embedded close to each other in lower dimensional feature space. Eventually encoder-decoder models helped us solve the Seq2Seq mismatch length problem, and then Attention allowed us to scale up this Seq2Seq contextual methodologies without any major bottlenecks or vanishing gradients, and all the while shifting their focus around altering word embeddings based on context. Transformers used Attention as the main component of their architecture so that there's no need to process data sequentially, they can run things in parallel, which enables deep learning models to focus on context far longer than before with hidden states. Multiple transformer models were trained, and were introduced to the public as open source models ripe for transfer learning, where you can introduce different tasks on top of the core models. As time goes, Few-Shot and Reinforcement Learning techniques are expected to create more state of the art models.
Computer Vision (CV)
Computer Vision (CV) focuses on replicating the human visual system to enable computers to identity and process objects in images and videos. The first research came from neuropsych research on cats, where scientists concluded human vision is hierarchical (like BERTs layers above) and neurons detect simple features like edges followed by more complex features like shapes, and then even more complex visual representations. This is the core idea of CV, and from this stem multiple different architectures for object classification, image captioning, image generation, and video generation.
Research in NN's started in 1959, and in 1969 was deemed "ineffective" because the single perceptron couldn't translate effectively to multi-layered NN's. This period lasted until 2010's (AI Winter) when the technological development of computer and internet became widely used. In 2012 Image Net Large Scale Visual Recognition Challenge had a model submitted from U Toronto named AlexNet that changed the CV field when it achieved an error rate of 16.4%.
CV also has supervised and unsupervised components similar to NLP:
- Supervised on labeled datasets
- Classification
- Regression
- Unsupervised for analyzing and clustering
- Clustering
- Association
- Dimensionality Reduction
- Self-Supervised
- Has taken over historic semi-supervised space
- Similar to BERT's next sentence prediction
- Ultimately stems from Contrastive Learning techniques
Some of Some of the main issues in CV revolve around
- Optimizing deep neural nets for image classification
- The accuracy typically depends on image metadata like width, height, resolution, and angle of reference.
- Methods exist for residual learning, expanded convolutional nets, and essentially "throwing more predictions at it".
- Scaling ConvNets, which can be scaled in all 3 dimensions: depth, width, or image size
- The question whether stacking more layers enables the network to learn better lead to deep residual networks called ResNet
- EfficientNet ended up scaling all 3 dimensions! It was bound to happen
ResNets were presented as an answer to "can stacking more layers enable the network to learn better" - the obstacle up to that point was vanishing / exploding gradients, and they were primarily solved for by normalized initialization and intermediate normalization layers which enabled networks with tens of layers to start converging for stochastic gradient descent with backprop. Degredation also proved to be an issue, where as network depth increased there was a saturation, and then rapid decrease, in accuracy. Adding more layers to a suitably deep model led to higher training error, and overfitting was not caused by this degredation. A shallower architecture was suggested, and using auxiliary layers consisting of identity mappings and others shallow model layers, but in practice this didn't help. Later on Deep Residual Learning took the charge - ultimately helping solve the degredation problem via residual skip connections, and in the future a combination of residual learning, normalization, and other tricks help to solve hese issues outright.
One of the most useful topics is getting more data without human supervision, and this is the core topic of Contrastive Learning which has helped these models greatly improve accuracy and reliability. The framework for CV is currently SlimCLR, and this has outperformed most work up to the 2020's, showing that more robust models can be created with larger / more comprehensive training datasets - the Contrastive Learning framework helps to generate that more robust and comprehensive data from open source datasets.
Self Attention in CV can also be used (they were made famous in NLP) by combining CNN-like architectures which were able to replace some convolutions entirely.
Merge
Over time, merging of modalities happened and now there are multiple models that can handle multiple modalities! Meaning one single model can handle multiple objectives, embedding output, and downstream tasks for both text and images. The "Hello World" of this is generating captions from images, or generating images from captions, which is what DALL-E 2 showcased in it's release. At the end of the day this is taking information from one modality, and making it available in a separate modality.
Finding datasets for multi-modality are increasingly difficult, BERT itself is pre-trained on open source datasets of almost 74 million sentences, and GPT-3 pre-training is comprised of five gigantic input datasets - no such datasets exist for high quality images to descriptions (multi-modal).
Evaluation
Finally, there's evaluation - which is the hardest part of any ML framework
Most evaluation frameworks in product based companies have more clear expectations, and revolve around making the company more money, engaging it's users, or ultimately some objective function. In multi-modal outputs, the text description could vary widely, and you need humans to give their subjective review of the input and output
Coding, Complexities, and Runtimes
This area is mostly theory and architecture, there's more code, theory, GPU optimizations, etc in the LLM Systems, Hardware, and Code Section