Generic Search System
Ecommerce Diagram
Below you can see a generic E-Commerce website setup that includes a recommendation system
This flow only includes the default user recommendations, and in other flows we'd have to include "current search item" or "returned order item" or something similar
The dotted lines represent our Filtering Steps which is the part of our rec service that should be fairly "online and up to date", whereas our Candidate Generation and Ranking are trained / updated over time, but not always "up to date"
The diagram below is for the Log-On scenario for a user, and doesn't include any query terms or search context. This "involved" diagram is one of the simpler cases!
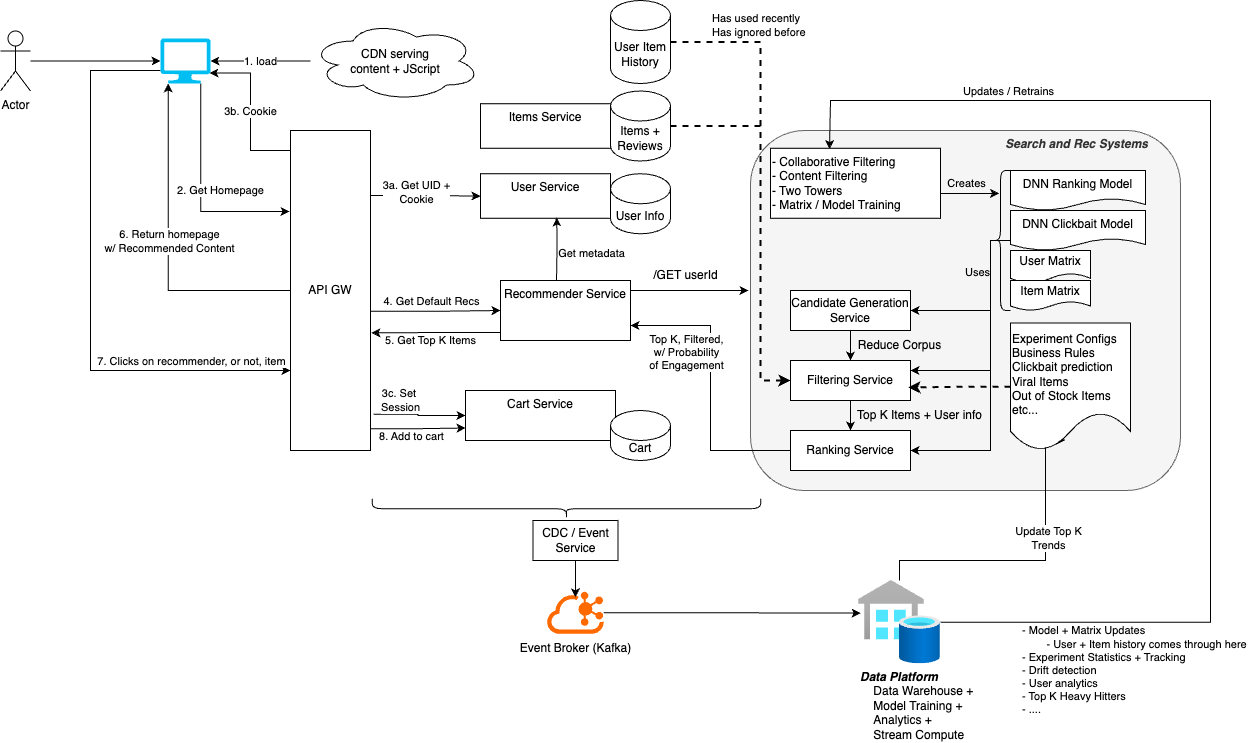
Architecture Component Notes
- You specify CDN + user sessions and cookies authentication flows because at a high level they show how you are going to run some sort of personalization
- You will process user + item history and eventually create interaction data in our data warehouse, and that's only possible if you have general click data
- Parallel / Concurrent calls
- Our calls to
/GET Homepageto our API GW and/GET Recs ? userId=...should happen in parallel, and each database should be able to handle async concurrent requests so that all of this info can get aggregated and returned to users browser
- Our calls to
- Rec System Engine
- Candidate Generation is a very important step that is typically looking to reduce the search space from millions to thousands or hundreds
- Recall is extremely important here as we desire to ensure our top candidates are included, but we want to get rid of the humongous population size of other non-top candidates
- Quickly (efficient model) retrieve the top-k candidates with high recall to pass on
- Filtering is stateful meaning it makes multiple database calls to other services - it is where you can inject experiments, place in ever-changing business rules, and really update it to anything you want
- Keeping a place to "remove any videos that are viral in Asia" is easier to do in a filtering phase with configs versus placing that logic in a model somehow
- Ranking looks to take the top-k results from candidate generation and filtering, and rank them with high precision to get to the top 1-3 total relevant items for a user. It focuses on high precision models
- In the proposal here it is using a DNN which should be trained for multi-task learning to ensure it maximizes engagement, conversion, usefullness, and other tasks. You don't cover that paradigm below, most of the DNN discussion is around "probability of engagement" or "predicted watch time" which are both prone to clickbait, but are an intuitive start
- Most of the time these issues would be handled in our Filtering phase with yet another model tied to it for predicting click-bait!
- In the proposal here it is using a DNN which should be trained for multi-task learning to ensure it maximizes engagement, conversion, usefullness, and other tasks. You don't cover that paradigm below, most of the DNN discussion is around "probability of engagement" or "predicted watch time" which are both prone to clickbait, but are an intuitive start
- Candidate Generation is a very important step that is typically looking to reduce the search space from millions to thousands or hundreds
- Event Streaming + Warehousing is used across the board for CDC from the databases to ensure you can run analytics and retrain models for future recommendation systems
- This system relies heavily on a Data Platform which is more than just a Data Warehouse which allows us to retrain models, run queries, and implement online and offline queries and transformations
- Top K Heavy Hitters is covered in another system design. We'd want to observe real-time trends, seasonal patterns, and viral content that can be used in filtering, non-NN based injection, and help with experimentation
- We can inject, randomly, top-k viral content into relevant items instead of having model try and include this in features
- This is all handled via an API Gateway, or typical frontend, which, along with proper load balancing and caching, can help ensure all of our requests are secure, correctly routed, and even minimal aggregation for returning to users browser
- It can also help with experimentation routing!
Search Systems
Search Systems (also Recommendation systems since you recommend something back) are used for finding relevant content based on a query
- "What day is it today"
- "Michael Jordan Dunk"
- etc...
All of these things are queries and we'd expect different content to be returned
Youtube will typically return Videos, Google will return almost any content type, App Store would return applications, and Facebook might return posts / users (friends)
An Example from Nvidia
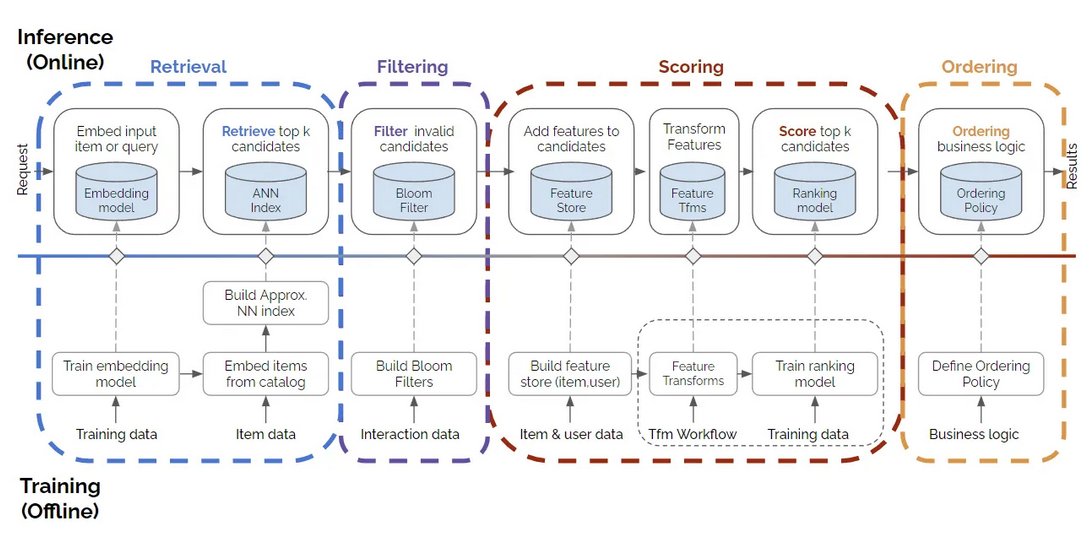
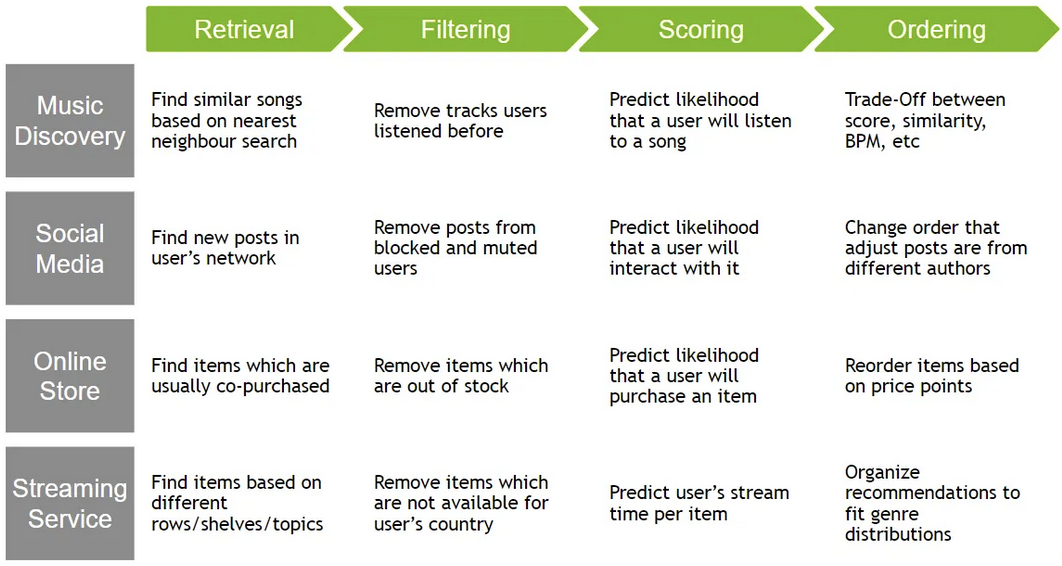
Terminology
- An item is generally the thing we'd want to recommend
- A user uses items and can be recommended items
- Users have a history of item usage
- A query comes in at some time, usually from a user, and you would recommend items for that query
- A query can be considered the general context / information a system uses to make recommendations
- An embedding is a way to create numeric representations of items, users, and queries which help us in the steps below
- Recommendation Scenarios:
- Log-On: When a user logs on and the system will recommend items to them
- Search: When a user queries for a specific item and you return items based on that query
- For each of the types above you will need to project the query context into some sort of embedding space and ultimately return some sort of Top K item results to the user
- General architecture:
- Candidate Generation: is where you efficiently distill the entire corpus of items down to a manageable size - this typically has high recall where you want to be certain you've included the relevant results while distilling the overall corpus to a more manageable size
- Recall is extremely important here as we desire to ensure our top candidates are included, but we want to get rid of the humongous population size of other non-top candidates
- Quickly (efficient model) retrieve the top-k candidates with high recall to pass on
- Missing a relevant item at this stage means it can never be recommended
- Filtering is another way to reduce the overall corpus with specific filters (IP address, geo-location, etc), inject experiments, place in ever-changing business rules, and really update anything you want with items you don't want to explicitly place into a model
- Retrieval and Scoring: is where you take the distilled space and run large scale heavy computations against the query / user context to decide on the best videos. This step typically has high precision where you want to take the distilled content and ensure the top results are pushed to the top of the list
- Re-Ranking: Takes into account user history, current trends, and other policies you might want to have included in our system that change more quickly. Typical policies include pirated content, child restrictions, user personalization, and clickbait removes, among many other policies. you woudln't want to include all of this in our generic candidate generation or ranking steps since it'd ultimately cause heavy retraining and recomputing of our Embedding Space
- Candidate Generation: is where you efficiently distill the entire corpus of items down to a manageable size - this typically has high recall where you want to be certain you've included the relevant results while distilling the overall corpus to a more manageable size
History
Over time recommendation / search systems have gone through a lot of changes
- At first you used inverted indexes for text based lookups of documents which would allow things like webpage lookup on google
- You can setup next letter prediction based on the Trie Implementation, and most of your iPhone's next word / letter prediction are based on Trie's and Word Embeddings
- Most of this stayed with token-based matching using more advanced methods like n-grams, maybe using distance metrics like Levenshtein, or even some minimal ranking with TF-IDF based methods
- The takeaway here was that you were always comparing text-to-text
- These systems had high precision, but low recall...if a word matches char for chat, it matches! But finding the matches that didn't 100% overlap became an issue
- Over time:
- Scale occurred:
- Recommendation systems started to span multiple content types, from videos to other users to generic multimedia, and the systems had to keep up
- Companies started to have humongous web scale for items like Amazon, Google, and Facebook
- These evolutions led to new search systems that had multiple stages across various content types which led systems to converge on Candidate Generation and Scoring over projected embeddings
- Embeddings occurred:
- you started to look to scores that could be calculated between
<query, candidate>pairs to give us high precision and higher recall
- you started to look to scores that could be calculated between
- Scale occurred:
Search has started to move away from returning items to returning summaries and question answering live through "GenAI", but in reality this is mostly still based on Transformer models and NLP tasks where you surround it with new context / query information
Here's a list of Examples from the Wild from NVIDIA
Inverted Indexes
Inverted Indexes have been around for a long time, and they built the original search systems you think of. When you hear of "Google indexed my page" or "Google crawled my page" it is referring to a system similar to this
There's many still used today, but for the most part systems require utilizing context, user features / demographics, and many other inputs to help design Search and Recommendation Systems
Embeddings
Embeddings are a way to create dense, numeric representations, that can have geometric operations like subtraction, addition, and "closeness", performed on them
- Word Embeddings are how you turn words into vectors, and was the start of most embedding models...everything changed when you started to use attention
- Sentence Embeddings are basically just aggregations of word embeddings, but things get a bit tricky and you start using multiple hidden layers
- Document Embeddings are basically just concatenated or aggregated sentence embeddings
- User Embeddings are typically created using User-Item interactions, along with other features like demographics, click through data, or history
- Embeddings can be created for almost anything, but at the end of the day the embeddings need to make sense for what you want to do, which is typically find "similar" things, or find geometric interpretations of "things" like Paris is to France as Berlin is to Germany
Scalable, Real Serving Systems
We'll walk through how serving systems would be architected in the current world
Candidate Generation
The Candidate Generation sub-document covers all main areas of candidate generation phase, but in most cases we'll basically be creating the user-item matrices as a batch at some specific time, and then updating it at some cadence as users interact with our service
If you choose to simply use filtering methods then all of the updates and batch creation can be done offline, and if you truly want our recommendations to be as up-to-date as possible we'd have to rerun the WALS update of user-item engagement each time a user uses our service
If you choose DNN, the DNN needs to be ran each time for a specific user to get the output Candidate Generation which leads us into ML Engineering Inference API's
Embedding Space Updates
How do you update our embedding space as users use our services?
you would need to capture the user click information as it's happening, and stream that data into a user database or an analytical data warehouse
User-Item Matrix Updates
Once the data is in some sort of processing engine, we'd need to update the specific pointed row-column corresponding to user on item . This might be incrementing some usage statistic, upadting metrics on the fly, or something else. This can be apart of Feature Engineering pipelines that run on streaming data
The toughest part will be recomputing the user-item embeddings using WALS or SGD, as we'd have to clone the matrix somewhere else or pause updates on it as you created our new latent matrices and during Matrix Factorization
Then as the user returns, we'd have updated embeddings to serve them with
DNN Retraining
The DNN needs to be ran each time for a specific user to get the output Candidate Generation, and updating the model parameters each time wouldn't be smart so DNN gets retrained as our training data drifts from our User-Item data
The data drift detection can be a separate background feature pipeline in our processing engine, and once there's a significant enough change you can schedule a new model to be trained for inference
Filtering
Since our Candidate Generation models must run in milliseconds over gigantic corpus, you shouldn't embed any sort of "business logic" inside of them - things like product being out of stock, product not being child friendly, or product being too far away. These things should be based on user-features, but shouldn't fluff up our Candidate Generation model
In the past a Bloom Filter, which is now common place in many scenarios, was used to disregard items that the user has already interacted with!
Bloom Filters are a way to quickly check if something is part of a set. Bloom filters are extremely fast probabilistic data structures - they are bit arrays that are set to all 0's and then you add items to it over time. When you add a new item you apply some hash functions to it, and the resulting index is updated to 1.
Therefore, when searching for a new item you apply the same hash functions to it, and if you find a 0 the item is definitely NOT in the list (high recall - no false negatives), but if there's a 1 the item is likely in the set (hash collisions could bring about false positives)
Once the filtering is done, you can send things through to Scoring
Scoring
Given a user coming online, or a query being submitted, how do you actually obtain a set of items to present? This is the main focus of Retrieval and Scoring, sometimes called Ranking, and there are even some Re-Ranking steps involved...
For a Matrix Factorization technique, we'd have the static embedding matrices sitting in an API or on disk somewhere for us to look up at query time. you can simply look things up from the User Embedding Matrix to get our query embedding
For a DNN model you need to run an inference forward-pass to compute the query embedding at query time by using the weights that were trained from DNN Updates
The algorithms described in Ranking and Scoring can also be used here - it's really a horse a piece and what features you put into each and the objective function they're trained to "solve"
- Typical Scoring features / policies:
- Geographic closeness for things like Restaurants and Bars
- User account features for personalization
- Popular or trending items for the day
This is typically done using heavier models, and / or new features & policies, to create a finalized list to present to the user
Heavier models would include things like DNN predicted user watch time of each video (item) from the final Candidate Generation list. In this case you could have a DNN for Candidate Generation over our entire corpus, and then another DNN with more hidden layers and features to predict watch time for each video, but some systems just combine these into one for latency requirements
Why do you split Candidate Generation from Ranking?
- Some systems don't!
- Some systems use multiple Candidate Generation models
- Some Ranking models use heavier sets of features or heavier models that can't run over the entire corpus
KNN
Once you have our query embedding you need need to search for the Top K Nearest Neighbors (KNN) items in the Item Matrix that are closest to - this is typically done with the Ranking and Scoring algorithms described elsewhere, which help us compute a score for our query across the Item Embedding Space
Pseudocode:
- Get the user’s embedding vector from (for the target user)
- Compute similarity scores between and every item vector in
- Most commonly, use dot product:
- You can also use cosine similarity or Euclidean distance
- Sort all items by their similarity scores (descending for dot product/cosine, ascending for distance)
- Select the Top K items with the highest scores
This is a fairly large and complex thing to do online for each query, but there are ways to alleviate this!
- If the query embedding is known statically, the system can perform exhaustive scoring offline, precomputing and storing a list of the top candidates for each query. This is a common practice for related-item recommendation.
- Use approximate nearest neighbors. Google provides an open-source tool on GitHub called ScaNN (Scalable Nearest Neighbors). This tool performs efficient vector similarity search at scale
- ScaNN using space pruning and quantization, among many other things, to scale up their Inner Product Search capabilities, which basically means they make running Dot Product search very fast, and they also mention support of other distance metrics like Euclidean
Most of the time computing Top K is very inefficient - approximate Top K algorithms like Branch-and-Bound, Locality Sensitive Hashing, and FAISS clustering are used instead
Locality Sensitive Hashing (LSH)
- Description:
- A technique for approximate nearest neighbor search that hashes similar items into the same bucket with high probability
- Reduces the dimensionality of the data while preserving similarity
- How It Works:
- Uses hash functions designed to maximize the probability that similar items (based on a distance metric like cosine similarity or Euclidean distance) map to the same hash bucket
- Instead of comparing all items, only items in the same bucket are considered for nearest neighbor search
- Use Case:
- Ideal for high-dimensional data and large-scale systems where exact search is computationally infeasible
- Commonly used in recommendation systems, plagiarism detection, and image similarity search
- Limitations:
- May miss some neighbors due to the approximate nature of the algorithm
FAISS (Facebook AI Similarity Search)
- Description:
- An open-source library developed by Facebook for efficient similarity search and clustering of dense vectors
- Optimized for both exact and approximate nearest neighbor search
- How It Works:
- Supports multiple indexing methods, including:
- Flat Index: Exhaustive search for exact results
- IVF (Inverted File Index): Partitions the dataset into clusters for faster approximate search
- HNSW (Hierarchical Navigable Small World): Graph-based search for high recall and low latency
- Uses GPU acceleration for large-scale datasets
- Supports multiple indexing methods, including:
- Use Case:
- Widely used in recommendation systems, image retrieval, and embedding-based search
- Scales well to billions of vectors with low latency
- Limitations:
- Requires tuning of indexing parameters for optimal performance
Reranking / Ordering
This final part of the model is to mostly filter out items that may have made it through and aren't useful...these reranking models are much more dynamic and trained on "current issues" like pirated sports streams or child restriction content which could change much faster than our generic ranking systems need to
Typical examples include:
- Clickbait videos
- Overtrending videos
- Videos that may not be part of a specific experiment
- Child restrictions
- Piracy restrictions
- etc....
It's just another way to pick down at the final list to make sure it's useful
Conclusion
Discussing Candidate Generation, Ranking, Retrieval, Scoring, and Reranking might be confusing and repetitive, but in reality all of these components can and do make up recommender systems. In most scenarios the algorithms discussed are used in possibly all steps, and some systems have multiple models of each type (for example multiple Candidate Generation and Reranking models) which all support creating and whittling away at a finalized recommendation list
This is all important because you want to engage users with relevant content without "being evil" - showing trending videos, clickbait videos, or pirated sports streams is hard to combat without all of this context, and at some points you don't want to include all of that logic in our ranking and scoring. The decision on which model to place where and for what reason is what makes up our recommendation sytem's choices
Youtube DNN System
Marked Up and Commented PDF Here
So what could Youtube use in it's recommender system?
Candidate Generation
- Candidate Generation is around finding a manageable set of videos to compare to an incoming user Query in a very short timeframe
- Youtube paper mentions "taking recent user history into context and outputting a small sample of videos (100's) from our total corpus"
- It will have high precision meaning anything it generates is most likely relevant to the user
- It "provides broad personalization via collaborative filtering"
- The actual DNN is a non-linear generalization of matrix factorization techniques
- This basically means they used to use matrix factorization techniques, and the DNN means to mimic that, but DNN's are more flexible (non-linear)
- They mention the CGeneration task is extreme classification
Ranking
- Ranking will take the output of Candidate Generation, which is high precision, and will create a fine-level representation for the user
- Ranking will have high recall to ensure out of the videos Candidate Generation finds, Ranking doesn't leave anything behind
- It ranks these videos with a rich set of Query (User) - Document (Video) Features
Learn To Rank
This would be a good first thought - you could basically have user context as input along with some previous history, and then you could rank potential videos that get passed through from Candidate Generation
Facebook Embeddings System
The Facebook Embedding Paper talks through how Facebook served personalized recommendations focusing on recommending groups, events, and other documents to users
In the past there was a text based boolean search engine, similar to Lucene indexes, and over time embeddings and user, geolocation, and social graph information was included to ultimately provide a much more mature recommendation system to users. Embeddings and the further feature categories covered a number of issues the boolean text filter system was unable to handle, and afterwards they could just include the actual embedding relevance in the boolean output! An example below shows how they can just include their model output when searching for John Smith in Seattle or Menlo Park
(and (or (term location:seattle)
(term location:menlo_park))
(or (and (term text:john)
(term text:smithe))
(nn model-141795009 :radius 0.24 :nprobe 16)))
In the past, they simply relied on the top portion without the bottom embedding results, and this allowed them to include radius level results for a query (i.e. include documents within a certain ball radius). The paper walks through how integrating a new embedding based result into their existing system was actually quite simple based on that SQL statement above
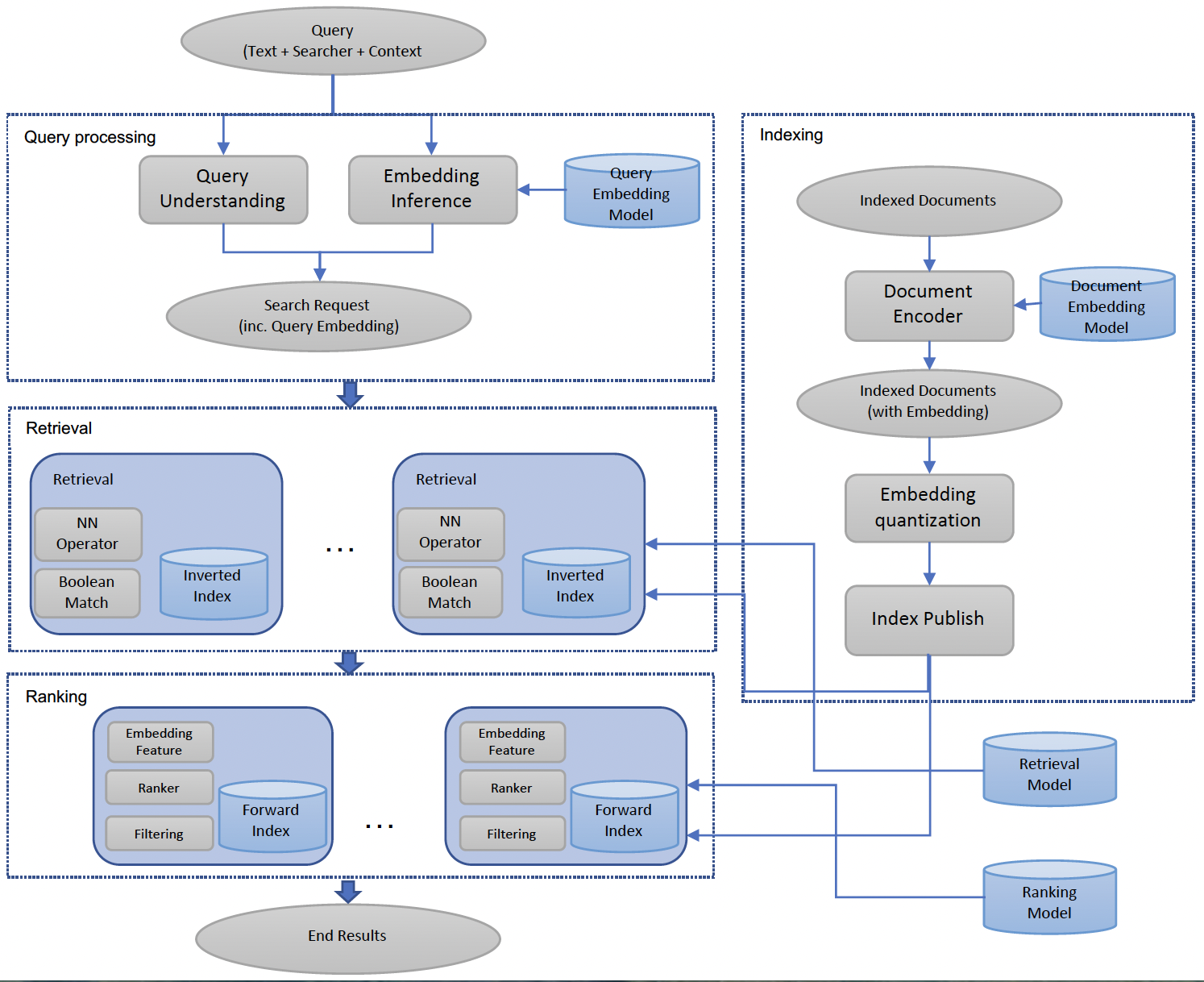
Components
The overall architecture followed a candidate generation / retrieval layer focused on targeting a set of relevant documents in low latency with low computation cost and high recall (they actually called it their recall layer). This was followed by a ranking layer tagreting to rank the most desired documents on the top via more complex algorithms and models (they called this their precision layer)
They utilized universal embeddings which combined query text, user features, geolocation, and local social graph embeddings to ultimately compare with other document embeddings in the same underlying metric space
After retrieving embeddings for similar query - document comparisons, these were fed into FAISS because ultimately at this point it was a K Nearest Neighbors problem
Training was able to be done via state of the art data mining methods, which utilized historic searches and click impressions for positives and a combination of random samples and hard negative samples (ignored presented impressions) for negatives
All of this was deployed and tracked via A/B experimentation to ensure further evaluation feedback loops were possible, and a large amount of the candidate generation layer retrieval stage was sent to human in the loop analysts to manually rank result sets to ensure that recall@k was appropriately calculated
Candidate Generation Retrieval
FB modeled retrieval task as a recall optimization problem looking to maximize recall@k - specifically given a query , it's target result set , and top results returned by the model the objective is to maximize
The target result set was created by human annotators who created ranked lists of relevances based on 10,000 historic queries and user sessions
The recall optimization, as a ranking problem, can be formulated by ordering the distances from the query to all documents via cosine similarity and triplet loss. For a given triplet , where is the query, is the positive document, and is the negative document, triplet loss can be defined as
Where:
- is a distance metric between document vectors and
- is the margin enforced between positive and negative pairs
- Tuning this margin parameter was found to greatly affect the resulting pipeline, and can cause differences of 5-10% recall variance
- is the total number of triplets selected from the training set
The intuition here is to separate the positive pair from the negative pair by a specific margin, represents the overall difference of distances from query to positive and negative, and ultimately means that as long as these two items are within a certain distance margin of each other, they'll be greater than 0 and the loss will be based on them
The negative examples were created via random sampling, there's further discussion in the hard negative mining section of the paper, but ultimately they found a selection of random sampling of negatives and hard mining was best, and random sampling alone outperformed hard negative mining alone. General intuition is that the model is forced to push the positive document to the top compared to all other documents, if we have documents, and , then our model needs to ensure the top document beats out 95 other negative random samples, and this ensures the recall model can retrieve documents from the full corpus appropriately
Negative hard mining would be more difficult, as the model needs to reason between very similar documents, and can't create the underlying embedding metric space appropriately so the model convergence is harder.
Unified Embeddings
To create unified embeddings, realistically all you need to change are the inputs to the encoders - conventional text embeddings are created from words, sentences, documents, whereas the unified embeddings consist of further contextual relationships around social graphs, user context, and relationships
Most of the input features to the encoder are high cardinality categorical features that are either one-hot encoded or multi-hot vectors - each of these categorical features will have a simple embedding lookup layer to transform it into a static dense vector, similar to Word2Vec except it would be for categories. Multi-hot vectors would have a weighted combination of multiple static categorical embeddings
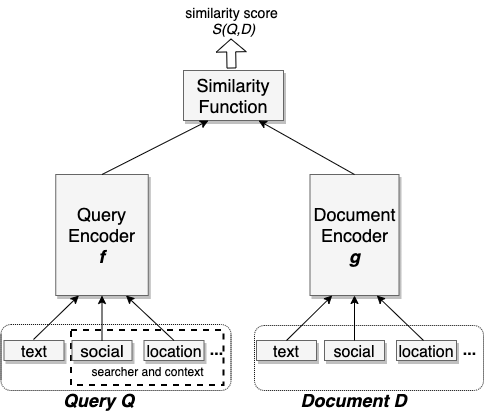
To actually optimize triplet loss, model was comprised of 3 main components:
- Query encoder
- Document encoder
- Similarity function
- Produces a score between query and document
- Just used cosine distance here, which ultimately measures angle betweeen two vector embeddings
Data Mining
As discussed above in candidate generation retrieval the actual process of getting positive and negative pairs (data mining) is hard for most ML systems, and especially for search systems
Positive pairs are "easier" as you can typically take clicked items as positives. There's some theories that mention these may not be the penultimate positives, but realistically there's no way to get a better result from historic log data without interviewing each person on what they'd have wanted at that exact moment. Negatives are even more difficult, and most systems look to use a combination of presented content that wasn't clicked, which are known as non-click impressions, and random samples of other items which are just random selections of other documents from the corpus
Thinking about the recall candidate generation layer, it needs to look at an entire metric space of documents and efficiently retrieve most relevant documents, and ensure that the top desired documents are inside of it. With contrastive triplet loss, the model continuously learns to separate bad from good, and to separate these two things inside of it's metric space - therefore learning to separate bad (random samples) of the corpus from good, makes sense. You push away all the random crap and focus in on potential relevant documents. If you use non-click impressions, those are much harder for the model to reason as they will most likely match the query on one to many features, and so the model is working to separate multiple similar documents in a regional area that ultimately don't help it to reason on separating relevant documents from the entire corpus. These findings were backed by facebook experiments:
- Model trained using non-click impressions as negatives had ~55% regression in recall as compared to the random sample negative model
- "We believe it is because these negatives bias towards hard cases which might match the query in one or multiple factors, while the majority of documents in index are easy cases which do not match the query at all."
Altogether, the data mining part + human ranking of top-k are two extremely important pieces as they directly affect model architecture, loss, and overall performance
Feature Engineering
All throughout the paper - unified embeddings are more effective than text embeddings
- +18% recall improvement in event search
- +16% recall improvement for group search
- Some other random things!
Thees unified embeddings success depended on bringing in relevant features, and using the features correctly. The below list of features shows how each modality was utilized:
- Text features
- Character n-gram are common approaches for using text for text embeddings, and typically outperform word n-grams
- Recent SOTE utilize special tokenizers to ensure word chunks and character chunks can be utilized appropriately
- This focuses on sub-word representations, and allows for full word representations via aggregations
- Helps with spelling errors
- Facebook Entity are representations of facebook objects that have text features
- Main attributes to extract were name for people, or title for non-people
- Embeddings trained on these text features helped to solve 2 major problems:
- Fuzzy text match: Can match "kacis creations" and "Kasie's Creations" page. Similar for "United States" and "America"
- Optionalization: In the case of queries like "mini cooper nw" the model can retrieve the expected "Mini Cooper Owners / Drivers Club" by optionally dropping "nw"
- Character n-gram are common approaches for using text for text embeddings, and typically outperform word n-grams
- Locations
- In order for embedding models to consider locations in generating output embeddings, the location features need to be added into both query and document encoders
- Query side extracted searcher city, region, country, and language into multi-hot vectors
- Document side extracted publicly available information such as explicit group location tagged by admin
- Adding these in as underlying features allows model to use locations to shift / alter the initial text only embeddings
- Social Graph
- The undrelying social graph has relationships between users, entities, etc
- FB trained a completely separate embedding model to embed users and entities based on the social graph which allowed them to incorporate sub-graphs into text + location embeddings
- Most likely relied on some sort of Graph NN to do node embedding, sub-graph embedding, etc for users and entities
- Output of this graph NN model can then be fed in as another feature layer
At the end of all of this, there is now full context for text, attributes, locations, and social graph / context into both the query and document encoders which ultimately help shift them in metric space so that the final distance calculation had more overall infromation to use for the final top nearest neighbor radius calculations
Serving
Serving each of these models, creating underlying embeddings, and the overall serving of the search system itself requires a fair amount of discussion. The paper itself mostly talks about how they integrated the new embedding based model into their existing system, and ensured their ANN models were efficient
ANN
The existing ANN model, employed via FAISS, is an inverted index with boolean terms that allows for efficient retrieval of top nearest neighbors to a query
The initial sentence sort of sums things up
We deployed an inverted index based ANN search algorithm to our system because of the following advantages
- First, it has smaller storage cost due to quantization of embedding vectors
- Second, it's easier to be integrated into the existing retrieval system that's based on an inverted index
The group mentions using FAISS to quantize the vectors and then implement the efficient NN search on the existing inverted table, and realistically FAISS takes care of most of this underneath the hood
- Coarse quantization quantizes embedding vectors into coarse clusters, typically through K-means
- Product quantization does a fine-grained quantization to enable efficient calculation of embedding distances
The tuning of all of the parameters in here is the major discussion point of this section of the paper, and the TLDR is you need an excellent lineage, experimentation, and testing service with evaluation datasets to ensure all of this can be finely tuned for production deployment
System Integration
The system integration piece was basically already talked about in the beginning sections, but the idea was to integrate this as another possible parameter in their SQL based retrieval
In the past, the query for finding John Smith in Seattle or Menlo Park would be
(and (or (term location:seattle)
(term location:menlo_park))
(and (term text:john)
(term text:smithe)))
Which was implemented via boolean matching over text attributes. This logic was still desired, and on top of that some groups wanted to implement AND and/or OR logic with the embedding implementations. Naturally, the thought was around extending this system to support the NN results via (nn <key> : radius <radius>) query operator which matches all documents whose key embedding is within the specified radius of the query embedding. The backend system serving these result queries would then go and call upon the backend inverted index FAISS system, to get the documents within a certain <radius>
At query time the (nn) is internally rewritten into an (or) of the terms associated to the coarse clusters closest to the query embedding (probes), and for matching documents the term payload is retrieved to verify the radius constraint - ultimately this means the coarse quantized clusters were used to reduce the initial document response space drastically, by finding all coarse clusters within that radius, and then for each actual document inside of these coarse clusters the payload there was compared to the query embedding. In this way you don't have to scan all documents for serving, just the ones inside of coarse clusters, which drastically reduces the number of comparisons needed
That logic above can be further extended into retrieving only the top documents closest to the query, and at that point the system was able to implement hybrid retrieval utilizing boolean expressions alongside NN expressions which allowed for fuzzy matching, spelling variations, optionalization, and inclusion of user, location, and social graph information without breaking backwards compatibility with existing systems
(and (or (term location:seattle)
(term location:menlo_park))
(or (and (term text:john)
(term text:smithe))
(nn model-141795009 :radius 0.24 :nprobe 16)))
Model Serving
- The query model was served via an online embedding inference service
- The document model utilized spark to do model inference in batch offline, and then published the generated embeddings toogether with other metadata into the forwad index
Further Topics
The 2 main further topics that were discussed were hard mining and embedding ensemble models
- Hard mining extended the loss functions, positives, and negative sampling criteria to include more robust distribution handling
- Embedding ensemble looked at utilizing multiple models to bring a more robust distance criteria by having weighted sums of models as the overall final metric
- It also looked into multiple models for candidate generation, filtering / further retrieval, and ranking. This is a common approach in most search systems today, and this topic explores how that can be done in their current system