Distributed Training
Distributed Training Theory
Tim Dettmers’ analysis of BERT training times shows that it would require about 396 days to train on a single GPU using Nvidia RTX 2080 Ti (the latest at that time). However, by going distributed (and buying 20 DeepLearning11 servers - the price in Oct 2018 is roughly 12k in 2 days is fantastic!
Most of these companies are running on large unstructured data, and so they'll be using other frameworks like Distributed TF on Ray or Distributed TF on Spark, which we get into in other sections
Distributed training can be done on a single machine, utilizing multiple CPU or GPU, or across machines utilizing all of the CPU / GPU across each machine. Distributed training is a strong scaling problem, meaning that communication is required between the GPU's / CPU's when going distributed. There's a threshold where the amount of time required to communicate updates in weights between GPU's grows linearly, and then network I/O can quickly become a bottleneck
Most of the time data processing and distributed training go hand in hand, but they don't necessarily have to - however, if you have a leader / worker setup the entire architecture of data processing and ML training is realistically the same thing. You calculate something over slices of data, and aggregate the results, and propogate that back across each worker
Distributed Gradient Calculation
The key piece that differentiates parallel, distributed ML training from typical parallel, distributed data processing is setting up the Gradient DAG computation, and efficiently updating the gradient based on the aggregation of it's parts
Taking a function , the gradient will most likely be a multi-variable vector showcasing the partial derivatives of each variable with respect to the function , but in our ML context most of the time these computations are chained together
At that point we apply the chain rule across each of these activation functions and computations, and compute the partial derivative for that specific step in the DAG - this is all done in Tensorflow for us, but combining these results so that the aggregation of parts is consistent with doing it all in one place is difficult
Most of the time Tensorflow's strategies, utilizing Mirrored Pooling Strategies, will take the gradients calculated on each worker over each mini-batch and aggregate them using summation or averaging
Most benchmarks between the frameworks / strategies shown below are ultimately outweighted by network I/O, which is by far the biggest threat to scaling a distributed training framework. Network I/O is the most common bottleneck when training. GPUs idle waiting for gradient updates from their neighbors. This is more likely to happen if you have a large model, too low network bandwidth between hosts, and/or too low memory bus bandwidth
Ring-AllReduce
Baidu Ring-AllReduce was one of the first major attempts at the distributed gradient updating problem, and in this format each node corresponds to a hardware accelerator (GPU). During training the nodes work in parallel to process a large mini-batch of training data, each node computes gradients on its local shard (aka partition) of the minibatch, and then each server will both send and receive gradients to/from their neighbors on a ring in a clockwise pattern
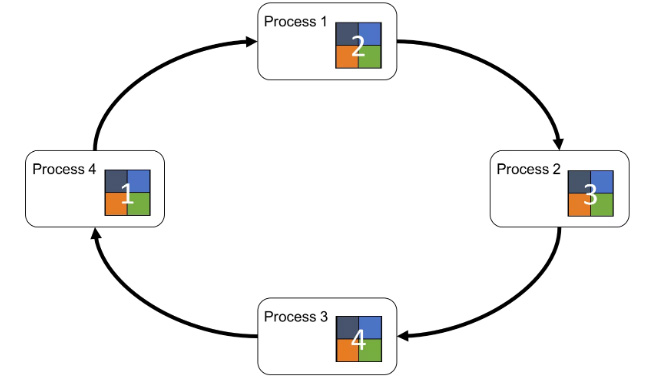
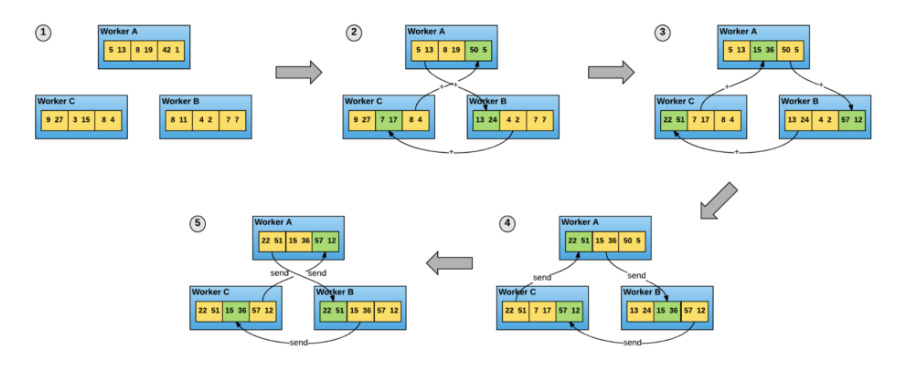
After all gradients have been forwarded to all nodes, the model on each node can be considered in consensus (equal) and the next mini batch can be processed
Horovod
In 2017, Uber released Horovod as a faster, easier library for distributed training of DNNs on Tensorflow, and then further extended for Keras and PyTorch. Horovod greatly outscaled parameter server models for distributed training, and required much less lines of code to create a Hello World distributed training script that ran
CollectiveAllReduceStrategy
This was a further extension of work done on both Horovod and Ring All-Reduce
Distributed Layers
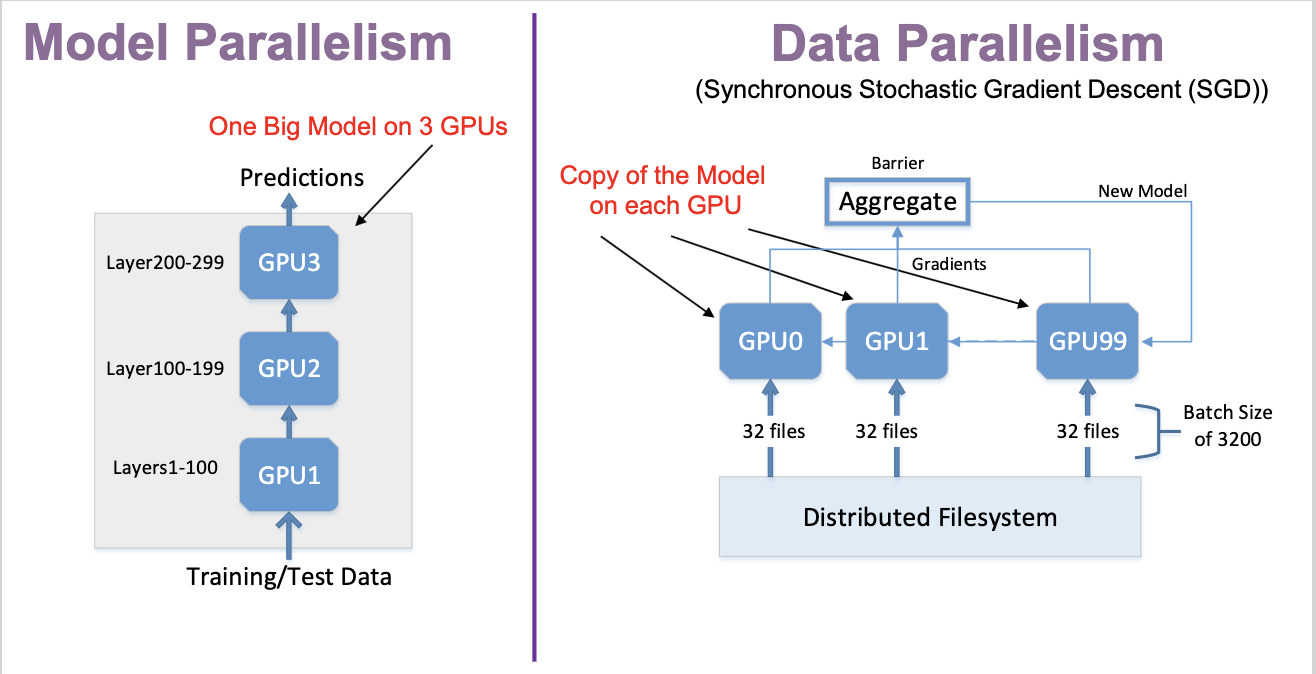
The other side of the coin is splitting up the gradient DAG, and effectively splitting up the layers - in this scenario you send all data into a worker that processes from layers , and then it would shuffle data to the next worker which computes and so on...
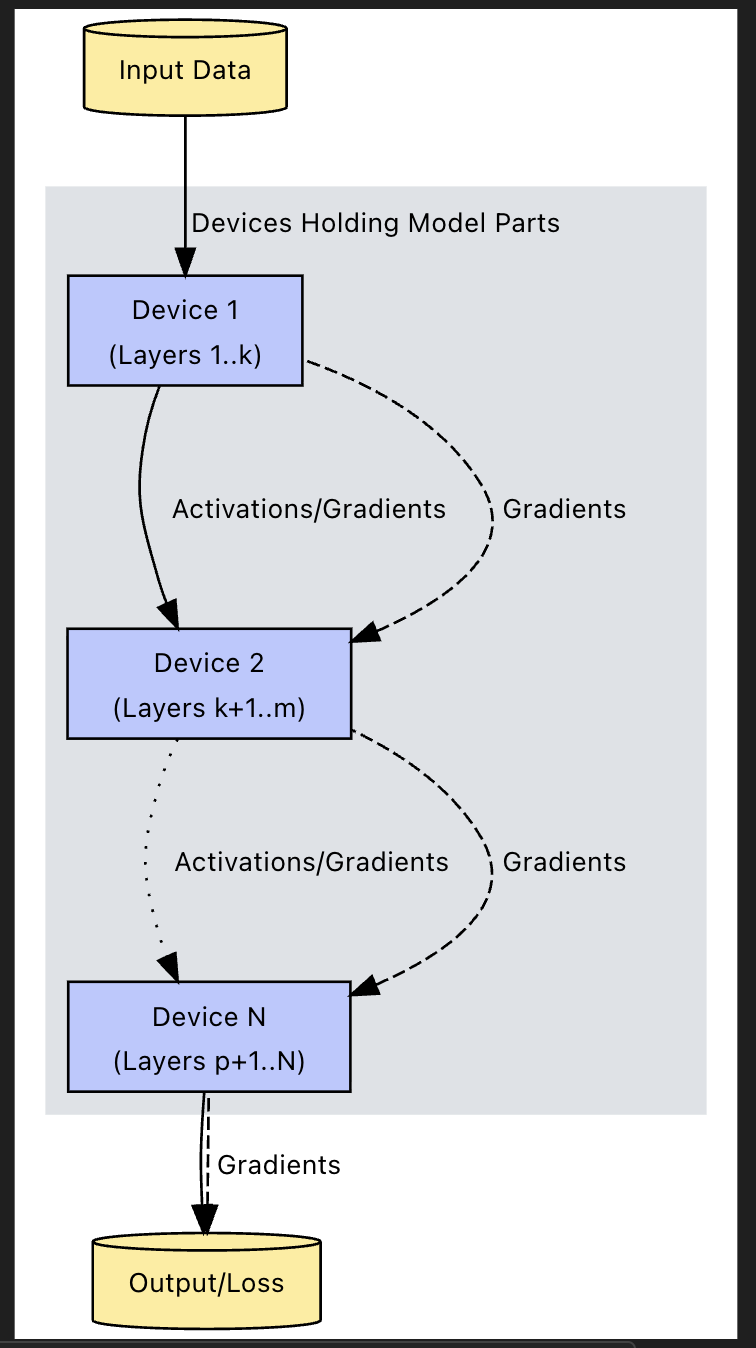
This is typically used when a single model and it's weights are literally too large to fit onto one machine, even with a small batch size being fed into it - gigantic LLM's and such may hit snags similar to this, especially when you're checkpointing model weights, historic computations, and other items during highly available training runs
Ultimately this is just performing logic (task) on data partitions, and so you'd expect the same machine to handle different data logic / layer computations - this may not be entirely true, so there are situations where this may be needed
In this setup the gradients and latest layer would need to be shuffled between workers
Distributed Tensorflow
Tensorflow is a generic ML modeling framework that helps to declare certain functionality and relieve some of the crappy numeric optimization and calculation steps that happen in bare-bones deep learning models
Things like overflows, log-mapping, etc... are handled by Tensorflow, and all of the numeric stability and chaining together layers is also handled out of the box
Strategies
Tensorflow bakes a few of these strategies into their framework so that you don't have to manage the complexities around updating DAGs or model layers from distributed workers - this involves registering workers, setting up coordination, and ensuring each model checks with each other or some coordinated leader before continuing any training
"The fundamental idea behind tf.distribute.Strategy is to encapsulate the intricate details of distributed training coordination"
The tensorflow strategies are meant to allow you to switch between Local Development Mode and true Distributed Training by wrapping up your local def train() function and sending it to each worker - the act of wrapping it up in it of itself marks the task as distributed and a need for coordination, otherwise it just assumes local
tf.distribute.Strategy acts as an intermediary between your Keras API training code, and the actual workers, multiple compute devices (CPU / GPU / TPU), and / or multiple processes
Core Functionality:
- Variable Distribution: It determines how model variables should be created and managed across the available computational devices. For synchronous strategies like
MirroredStrategy, this typically involves mirroring variables on each device. For asynchronous strategies, variables might reside on dedicated parameter servers - Computation Replication: It takes the computational graph defined by your model and replicates the forward and backward passes across the participating devices or workers
- Gradient Aggregation: It implements the necessary communication protocols (like all-reduce) to collect gradients computed on each replica and aggregate them (usually by summing or averaging) before applying updates to the model variables. This ensures consistent updates in synchronous training
- Data Distribution: It integrates with tf.data.Dataset to automatically shard or distribute batches of data to the appropriate devices or workers, ensuring each replica processes a unique portion of the data in each step (for data parallelism)
Mirrored Strategy
On a single machine, with multiple GPU or CPU, you might use tf.distribute.MirroredStrategy, which creates copies of all model variables (mirror) on each GPU and uses all-reduce to aggregate gradients

MirroredStrategy is synchronous, meaning all devices must complete their computations before proceeding to the next step, and then shared across to each other GPU before continuing
Altogether it's quite simple:
- Duplicate the model
- Mirror variables, optimizers, etc onto each device, specifically cloning required variables onto GPU
- By default it utilizes all available GPUs, but you can specify a subset
- Entire model and variables need to fit on each GPU
- Split the work / data (Data Sharding)
- Each incoming batch of data is divided evenly across all GPU replicas
- Example:
- 4 GPU's
- Global batch size of
- Each GPU processes a local batch of
- Each GPU computes forward and backward passes independently
- Each GPU computes the loss and gradients based on its local batch
- Synchronize the results back together
- Aggregate gradients using all-reduce from each GPU in a central process
- May also utilize a library like NVIDIA NCCL for efficient communication from GPU-2-GPU without a central coordinator
- Update model variables on each GPU with the aggregated gradients to ensure consistency across all replicas
- Aggregate gradients using all-reduce from each GPU in a central process
- Continue to the next batch

MultiWorkerMirrored Strategy
For multi-machine setups, tf.distribute.MultiWorkerMirroredStrategy extends this concept across multiple machines, coordinating variable updates and gradient aggregation over the network
The TLDR is that we do the same overall distributed strategy, except instead of multi-process communication we now need to do multi-machine communication. Ultimately, it requires us to configure environment variables that specify host:port for every worker so that the machines apart of the cluster can reach each other - these are set in the TF_CONFIG environment variable on each worker
An example of setting for worker0 - each worker gets the same config except it's index: <int> is supposed to represent which worker it is:
export TF_CONFIG='{
"cluster": {
"worker": ["worker0.example.com:2222", "worker1.example.com:2222"]
},
"task": {"type": "worker", "index": 0}
}'
For data sharding, compute strategy, and other coordination tactics there's now 2 components - the number of workers, and the number of GPU's on each worker
- Global Batch Size = # of records in total over all workers
- Machine Batch Size = # of records that are sent to each VM
- Machine Batch Size = Global Batch Size / # of workers
- Per Task Batch Size = # of records that are sent to each GPU
- Per Task Batch Size = Machine Batch Size / # of GPUs per worker
So if we have global batch size, workers, and GPUs per worker, each VM processes samples, and each GPU will ultimately end up processing samples
The gradient calculation, forward pass, and all-reduce synchronization methods are the same, except we now share with many more GPU's that also need networking connectivity

Some considerations must be taken into account for network shuffle, hyperparameter tuning and learning rate updates, and saving and checkpointing:
- Network shuffle is not a joke - there will be GB of data being passed around workers, and it's important to ensure that the network can handle this load without becoming a bottleneck
- Hyperparameter tuning and learning rate updates may need to be coordinated across workers to ensure consistent training dynamics, and specifically there are
num_replicas_in_syncextra gradient updates (larger total batch size) so exploding and vanishing gradients are more likely to occur (extra samples added in), particularly when using techniques like gradient accumulation which make debugging difficult - Saving and checkpointing models must also account for the distributed nature of training, ensuring that all replicas are synchronized and that checkpoints are consistent across workers
- Having a highly available, durable, and fault tolerant cluster setup is a critical requirement that comes with it's own set of distributed software engineering challenges
- Typical CAP theorem problems arise, and ensuring consistency while maintaining availability and partition tolerance can be difficult in practice
Distributed On Spark
In Spark the above concepts are known as Tasks, Stages, and Shuffling for the most part - tasks are individual logic we can apply on partitions of data, and stages are groupings of tasks separated by shuffling data between workers
In the ML training world, you partition your input data into batches (partitions), you compute some business logic, most of the time it's a forward pass and gradient computation (task), you aggregate the results (map-reduce / aggregation) onto the "coordination worker" who stores the sum of all workers, and then you reveal those gradient updates back to each worker (shuffle)

Spark is a typical framework for doing distributed training as it's such a robust toolset, but there are so many other frameworks that help to coordinate the leader / worker paradigm and go beyond the typical toolkits that Spark provides - these are led by tools like Ray, Horovod, and the big cloud providers who wrap these up into highly available services
Spark itself only provides some generic toolkits from PySpark MLLib, and Tensorflow-Spark-Connector, but most of the time they work well out of the box
The rest of the below discusses Tensorflow Distributed Architecture, because Tensorflow lends itself to distributed training and tools like Spark, Ray, etc. take advantage of these distribution strategies and package them up for you
The problems below are covered by some distributed computing frameworks like Spark and Ray, and that's what they give you! Highly available and durable training runs:
- Communication Overhead: Moving data, activations, and gradients between devices (across PCIe buses on a single machine or network interfaces between machines) takes time and can become a significant bottleneck, especially as the number of workers increases. The ratio of computation time to communication time is a critical factor in determining the efficiency of distributed training
- Synchronization and Consistency: Ensuring that all workers are operating on consistent versions of the model parameters is important, particularly in synchronous data parallelism. Asynchronous strategies trade consistency for potential speed, introducing challenges related to gradient staleness
- Fault Tolerance: In large distributed systems, worker failures become more probable. A distributed training framework needs mechanisms to handle such failures without losing significant progress
- Debugging: Identifying and fixing issues in a distributed environment is inherently more complex than debugging a single-process program. Problems might arise from network issues, synchronization errors, or subtle differences in worker environments
Actual Coding Mechanisms
Getting this to run over parallel datasets takes some gruntwork/ Everything for running TF on Spark in a distributed strategy involves using wrappers, decorators, and API's correctly
spark-tensorflow-distributor package is the go-to for actually running all of this, and has replaced some of the older solutions like Horovod
The train(batch_size) method is the main driver between running in local mode and distributed mode - local is just MirroredStrategyRunner with one worker (driver only), and so there's no actual variable mirroring that's needed, which allows it to be "local"
Imports need to be done inside of the train() function, because Spark will do some library pickling and serializing on each executor, and it's mostly easier to ensure these are imported on each executor at runtime. Below is a single-node training loop that's just indented over under train()
def train(batch_size):
import tensorflow as tf
import numpy as np
import uuid
def make_datasets(batch_size):
(x_train, y_train), _ = tf.keras.datasets.mnist.load_data()
# The `x` arrays are in uint8 and have values in the [0, 255] range.
# You need to convert them to float32 with values in the [0, 1] range.
x_train = x_train / np.float32(255)
y_train = y_train.astype(np.int64)
train_dataset = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(BUFFER_SIZE).repeat(2).batch(batch_size)
return train_dataset
def build_and_compile_cnn_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(128, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(256, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(512, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'],
)
return model
train_datasets = make_datasets(batch_size)
multi_worker_model = build_and_compile_cnn_model()
# Specify the data auto-shard policy: DATA
options = tf.data.Options()
options.experimental_distribute.auto_shard_policy = \
tf.data.experimental.AutoShardPolicy.DATA
train_datasets = train_datasets.with_options(options)
multi_worker_model.fit(x=train_datasets, epochs=3)
from spark_tensorflow_distributor import MirroredStrategyRunner
# This runs in local mode
BATCH_SIZE_PER_REPLICA = 512
runner = MirroredStrategyRunner(
num_slots=1, local_mode=True, use_gpu=USE_GPU)
runner.run(train, batch_size=BATCH_SIZE_PER_REPLICA)
In the MirroredStrategyRunner, the local_mode=False parameter runs train() function on worker nodes instead of driver. Hypothetically, you can just set NUM_SLOTS to whatever your GPU count is, and set local_mode and just start running on a cluster. It should run out of the box, but it probably won't be optimal usage of GPU / CPU and might actually be slower than a single node at first
NUM_SLOTS = TOTAL_NUM_GPUS if USE_GPU else 4 # For CPU training, choose a reasonable NUM_SLOTS value
runner = MirroredStrategyRunner(num_slots=NUM_SLOTS, use_gpu=USE_GPU)
runner.run(train, batch_size=BATCH_SIZE_PER_REPLICA*NUM_SLOTS)
The main recommendations for actually getting things optimized so that a distributed run is faster than a single node run revolves around:
- Uptime, availability, and optimization of input data, which is the standard thought process when running Spark for even just data processing, and is covered by the 5 S's of Spark
- Throughput, by ensuring the
BATCH_SIZEis large enough to fit into one pass of GPU memory and ensuring the full unskewed load goes through- Relates to skew, total batch size, total dataset size, and data generation / relationships
- Data generation, which combined with throughput relates to how data is actually being fed into each executor. Setting up partitions correctly, ensuring serialization from JVM to Python, vectorized predictions, and actual passing of JVM based RDD's through a PySpark model running Tensorflow
- Serialization, which is the burden of all things PySpark, Tensorflow-On-Spark, etc is combined with the 2 above recommendations where we want to ensure data isn't being replicated, duplicated, or unnecessarily transferred as much as possible, and that we're actually running vectorized SIMD operations
How do we run a matrix of weights across serialized input data, and then compute gradients? And how do we do that at scale with batch sizes across JVM's hosting RDD's and python workers who expect NumPy or Tensors?
Addressing The Above Recomemendations
So how are these addressed in all of the frameworks?
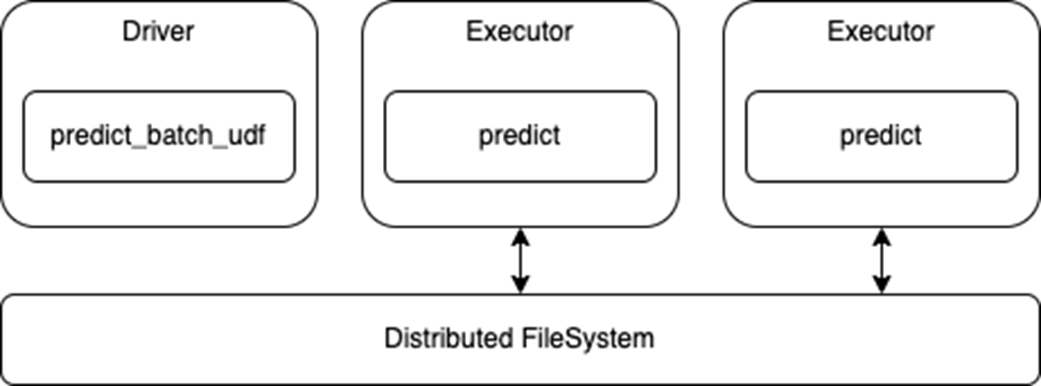
The predict_batch_udf function introduces some standardized code for:
- Translating Spark dataframes into NumPy arrays, so the end-result DL training / inference code doesn't need to convert from Pandas
- Batching the incoming NumPy arrays for DL frameworks
- API uses standard Spark dataframe for inference, so executors read from distributed file system and pass that data to
predictfunction, so any small pre-processing can be done inline with model predictions
- API uses standard Spark dataframe for inference, so executors read from distributed file system and pass that data to
- Loading models (serializing) onto executors to avoid pesky serialization issues, and utilizing
spark.python.worker.reuseconfiguration to cache models in Spark executors- This does require the model fits entirely into
spark.executor.memory, however large it is
- This does require the model fits entirely into
A small example below shows how this function has all of that wrapped underneath it, and will be sent in it's entirety to each executor to run, and then the predict_batch_udf will act as some sort of driving map type code on the df.withColumn call:
from pyspark.ml.functions import predict_batch_udf
# define everything we need in a function,
# similar to train() as explained before
def make_predict_fn():
# load model from checkpoint
import torch
device = torch.device("cuda")
model = Net().to(device)
checkpoint = load_checkpoint(checkpoint_dir)
model.load_state_dict(checkpoint['model'])
# define predict function in terms of numpy arrays
def predict(inputs: np.ndarray) -> np.ndarray:
torch_inputs = torch.from_numpy(inputs).to(device)
outputs = model(torch_inputs)
return outputs.cpu().detach().numpy()
return predict
# create standard PandasUDF from predict function
mnist = predict_batch_udf(make_predict_fn,
input_tensor_shapes=[[1,28,28]],
return_type=ArrayType(FloatType()),
batch_size=1000)
# get data
df = spark.read.parquet("/path/to/test/data")
# run it
preds = df.withColumn("preds", mnist('data')).collect()
Distributed on Ray
Distribution on Ray is a similar setup as Spark, except Ray is a lot better at unstructured data and pointed API inference