LLM Systems, Hardware, and Code
LLM Systems, Hardware, and Code
In the transformer and llm section, we cover the theory behind LLM's, Transformers and Attention, and specific models like BERT and GPT. In this section, we cover the systems, hardware, and code that make it possible to train and run LLM's at scale, and talk about some of the systems behind them like training, inference, optimizations, and more
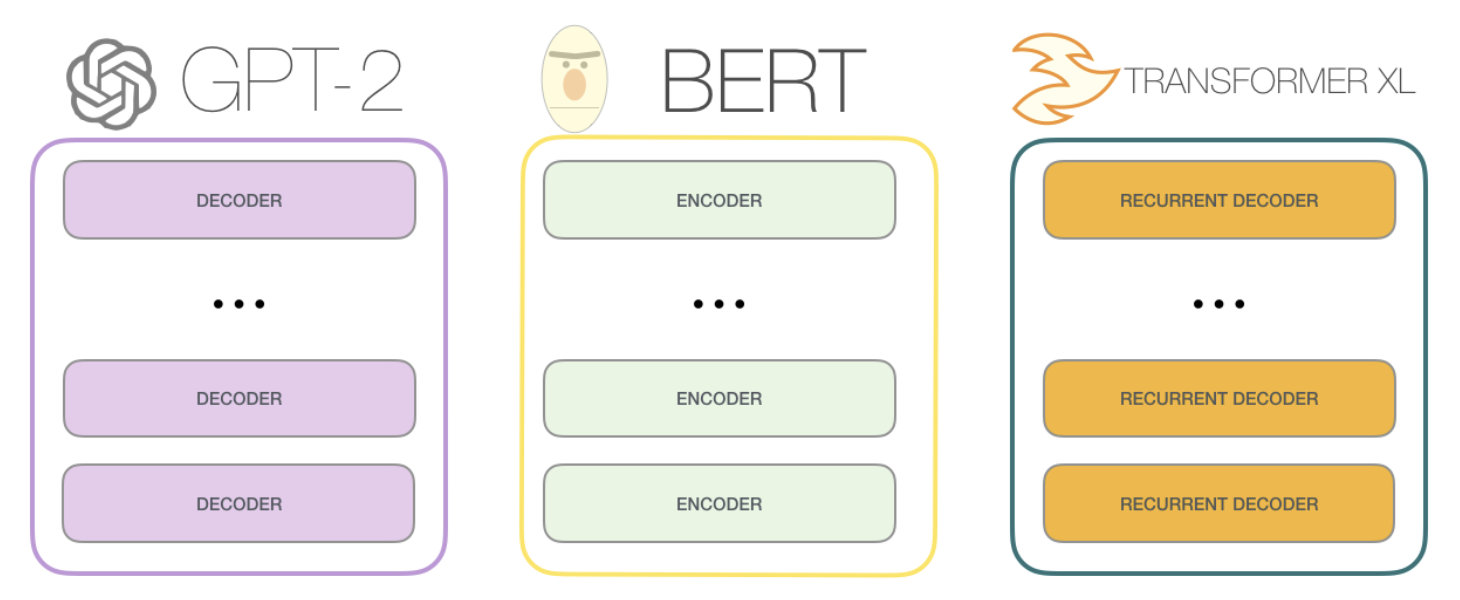
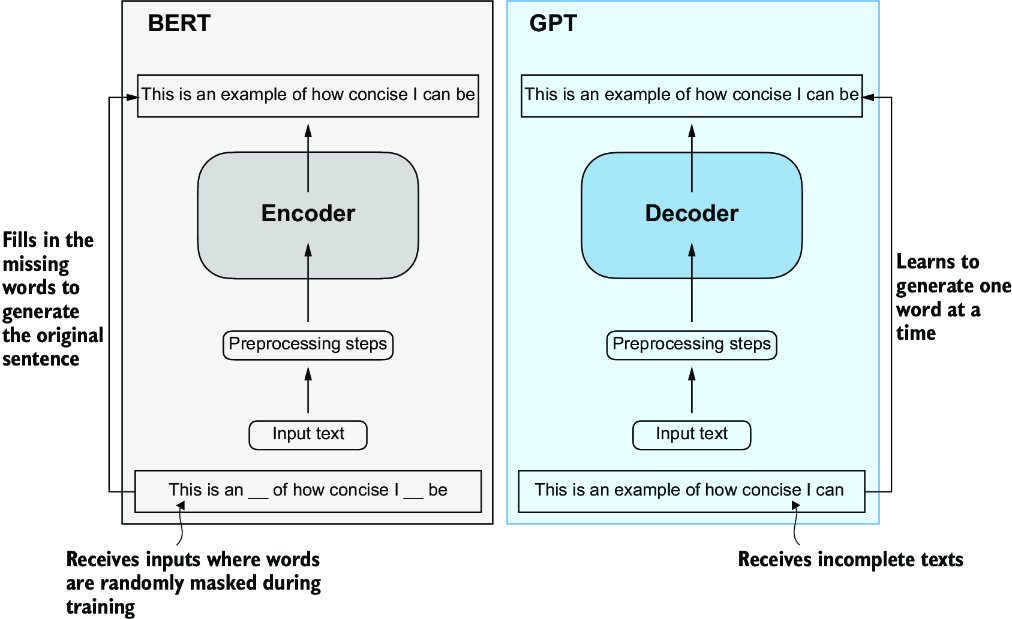
Training
LLM Training is done over gigantic corpa of data, and requires a lot of compute. We talk about the systems behind training, including data pipelines, distributed training, and more
Most of these systems have Human In The Loop components where human feedback is used to improve the model, and that will get into how a sentence with multiple potential outputs is framed as a reward function for the model to optimize for, and how that is used in practice to train LLM's
Various training datasets are used, mostly around sourced web content from social media, online encyclopedias, and structured curated text
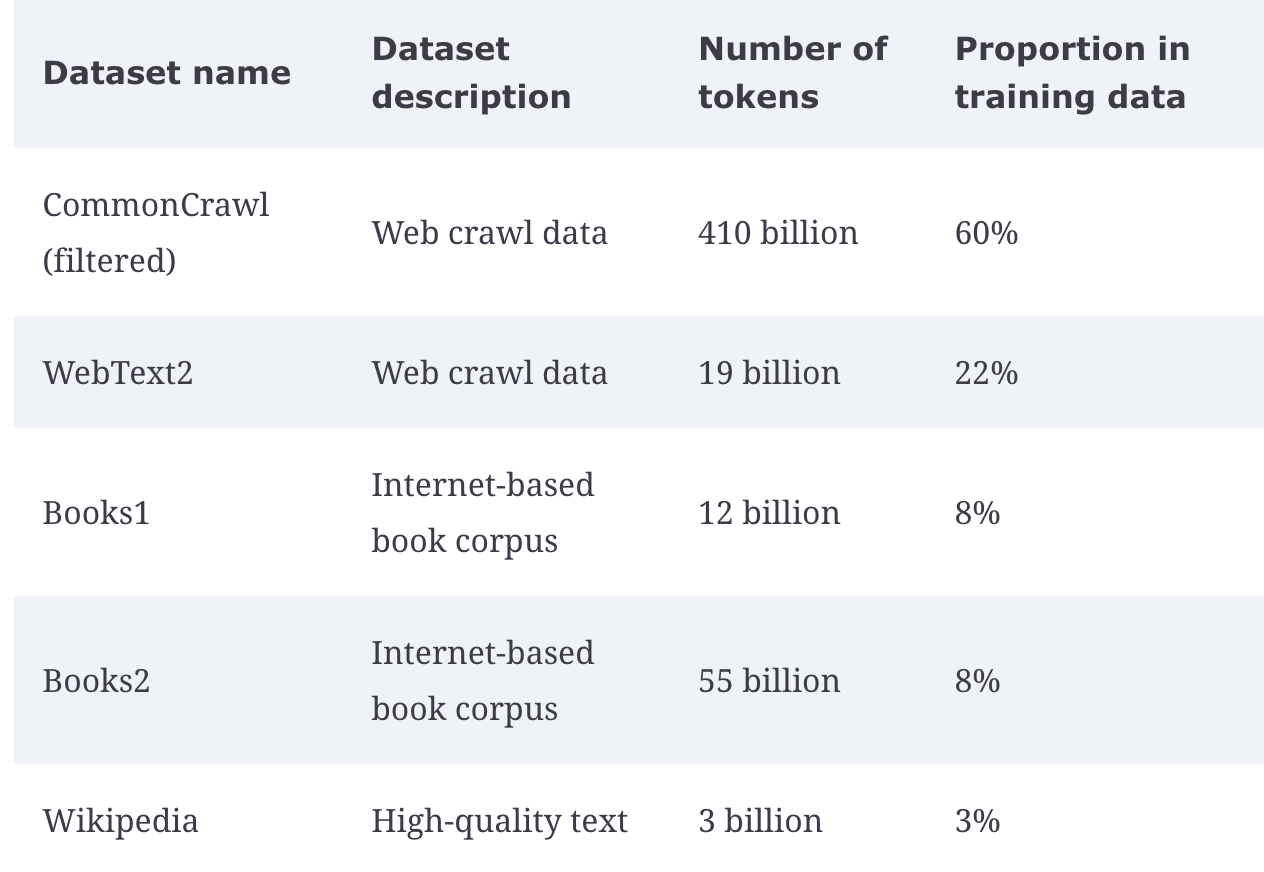
Metrics
- Utilization = Output achieved Capacity paid for
- GPU Allocation Utilization = GPU-seconds running application code GPU-seconds paid for
- GPU Kernel Utilization = GPU-seconds running kernels GPU-seconds paid for
When utilizing GPU's, there are a few metrics to use to figure out how much you get out of it. The time to actually reserve, setup, and place code onto a GPU is known as Allocation, and then once code is sitting on the GPU the actual utilization of SIMD processing, which is commonly known as kernel compute, showcases our actual ability to use the GPU for what it's best for
Just because an allocated GPU is running application code doesn’t mean it is running code on the GPU. The term of art for “code that runs on the GPU” in the popular CUDA programming model for GPUs is “kernel”, and so we call the fraction of time we spend running code on the GPU the GPU Kernel Utilization
This utilization metric is reported by, among others, the beloved nvidia-smi command line tool wrapping NVIDIA’s Management Library for their GPU hardware, and so it is commonly checked and cited
References
Wanted to give explicit references here because a lot of this has come from various websites, but pulled info from specific book below
Sebastian Raschka Book was a great resource, along with some of his personal website and blog posts