Event Loop + CPU and I/O Bound ML Example
Event Loop
The first start of any event driven software system is the event loop - which is just a continuous, non-blocking, asynchronous loop that pushes new requests to other queue's / files to handle later on by some other process
while True:
# Blocks until some registered file descriptors are ready, with an optional timeout
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
# New connection ready to be accepted
accept_wrapper(key.fileobj)
else:
# Existing connection ready for I/O service
service_connection(key, mask)
Event loops are core components in API's, streaming frameworks, and pretty much anything software, coupling this with concurrency, multi-threading, multi-processing, etc in different languages like Python (which has the GIL issue), Java, C++, etc all means there's no "one size fits all" solution
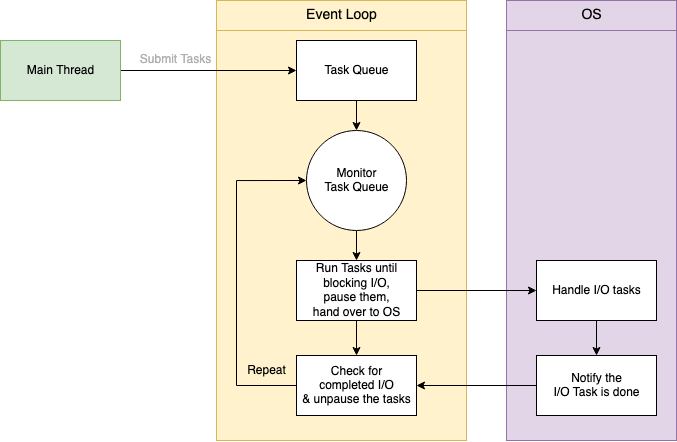
Covering the main aspects, theory, and implementations of event loops in Python first without parallel multi-threading, and then in Java / Go which utilize different mechanisms for concurrency and multi-threading, will give us a good start to how events can be processed in different languages
The main use case of an event loop is to have something (a thread) that can accept connections over multiple sockets, and can pass on these connections and future work to other processes / threads to do actual work. The event loop should continuously run and ensure that as soon as a new connection reaches a socket, it's ingested to be processed. There's no way to continuously check sockets except for a while True: loop
There's more theory in the sockets document around:
- Select
- A proper application server
- I/O vs CPU Bound
- Event loops can be blocked by CPU Bound work in a single threaded (Python GIL) environment, and so they're best for I/O bound work or passing off work to other processes
- AsyncIO and other frameworks help with I/O bound applications, they won't do much for CPU bound
- We can copy a model-per-process in Python to get to multi-processing CPU abilities, but the memory and communication overhead is high
- Outside of that, there needs to be centralized communication between processes which typically involves queue's, pipes, etc from the main
multiprocessingfork. If this main portion fails, there's no graceful recovery multiprocessingdoes allow for listeners and clients which are wrapped upsocketswithsend() and recv()implemented
- Outside of that, there needs to be centralized communication between processes which typically involves queue's, pipes, etc from the main
Show Python Script
import selectors
import socket
import types
# Create a default selector
sel = selectors.DefaultSelector()
def accept_wrapper(sock):
"""Handles accepting a new connection."""
conn, addr = sock.accept() # Should be ready to read
print(f"Accepted connection from {addr}")
conn.setblocking(False)
data = types.SimpleNamespace(addr=addr, inb=b"", outb=b"")
# Register the new connection for reading
events = selectors.EVENT_READ | selectors.EVENT_WRITE
sel.register(conn, events, data=data)
def service_connection(key, mask):
"""Services an existing connection."""
sock = key.fileobj
data = key.data
if mask & selectors.EVENT_READ:
try:
recv_data = sock.recv(1024)
if recv_data:
data.inb += recv_data
data.outb += b"Echo: " + recv_data # Prepare response
else:
# Connection closed by client
print(f"Closing connection to {data.addr}")
sel.unregister(sock)
sock.close()
except BlockingIOError:
pass # Expected in non-blocking mode
if mask & selectors.EVENT_WRITE:
if data.outb:
try:
# Send the response
sent = sock.send(data.outb)
data.outb = data.outb[sent:]
except BlockingIOError:
pass # Expected in non-blocking mode
# Set up the listening socket
host = '127.0.0.1'
port = 65432
lsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
lsock.bind((host, port))
lsock.listen()
lsock.setblocking(False)
print(f"Listening on {(host, port)}")
# Register the listening socket with the selector to monitor for read events (new connections)
sel.register(lsock, selectors.EVENT_READ, data=None)
# The main event loop
try:
while True:
# Blocks until some registered file descriptors are ready, with an optional timeout
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
# New connection ready to be accepted
accept_wrapper(key.fileobj)
else:
# Existing connection ready for I/O service
service_connection(key, mask)
except KeyboardInterrupt:
print("Caught keyboard interrupt, exiting")
finally:
sel.close()
lsock.close()
Callbacks
Callbacks are essential as they allow the main event loop thread to communicate with other processes / threads - the background processes need to return the output, results, event, etc back to the main thread to return back to the client. A callback is registered to handle the result of an operation (like a network request, file read, or ML inference). So when the operation finishes (possibly in the background), the event loop or worker thread invokes the callback, passing it the result - this allows the main thread to remain responsive and not block while waiting for this background operation to complete
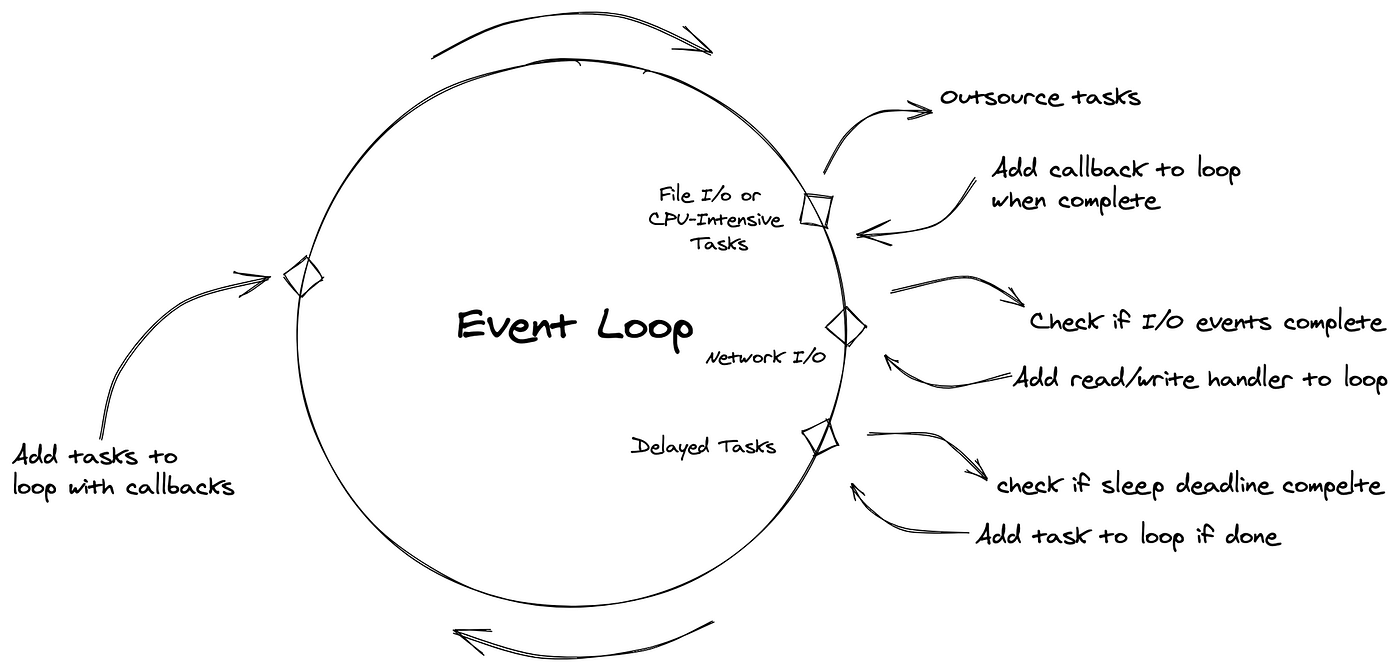
In something like Java, the typical event loop for an ML model inference would revolve around accepting new POST requests from a client, and passing off the actual request to background processes in true parallel processing fashion:
- Event Loop Thread
- Listening on a specific Socket (IP + Port)
- Accepts the client POST request
- Submits the ML inference task to a thread pool
- Registers a callback (often as a lambda or via
Future/CompletableFuture
- Worker thread(s) on another core
- Runs the ML inference in the background
- When done, the worker thread itself executes the callback
- Callback
- The callback (which sends the result back to the client) is executed by the worker thread that finished the task
- If you want the response to be sent from the main event loop thread (for thread safety or framework requirements), you must explicitly schedule the callback to run on the event loop thread (e.g., using a queue or framework method)
ExecutorService pool = Executors.newFixedThreadPool(10);
void handlePostRequest(Request req) {
pool.submit(() -> {
Result result = runMLInference(req.data);
// This callback runs in the worker thread!
sendResponseToClient(req, result);
});
}
ML Inference Example
ML Inference is typically a useful example as you have high I/O procesing when a client sends a request to get the model output, and in the middle there may need to be features, cache lookups, etc done alongside the input data (like user items), and then it turns into a CPU bound process to actually run model weights against input before returning it to the client
So how can we build a low latency, high concurrency, CPU / GPU saturated model serving framework? Start by looking at requirements:
- Need to ensure all CPU / GPU are utilized to their fullest abilities
- Need to ensure batching is done
- Model per core, or even multiple model per core
- CPU needs to handle I/O and offloading to background processed
- Extremely high I/O rates (1,000+ req/second throughput) from clients and any databases / lookups
- All the rest of the CPU / GPU cores can be completely utilized for inference (CPU bound)
- Read heavy workload, models won't be changing inside of the actual containers
There can be an orchestration layer that handles I/O, client connectivity, etc in one language that calls CPU bound heavy workloads in another language. Data serialization between the two can be done via [gRPC](/docs/architecture_components/communication protocols/grpc.md) so that each language can efficiently serialize and deserialize incoming data. This doesn't force microservices on us as this can all be deployed in containers on a singular VM based on the number of cores on each, or this could be migrated out into microservices as well fronted by load balancers - no major difference other than network hops and discovery. Funny enough, this is how NVIDIA Triton Servers are setup to run, including Triton gRPC, Triton Batching, and Triton Caching
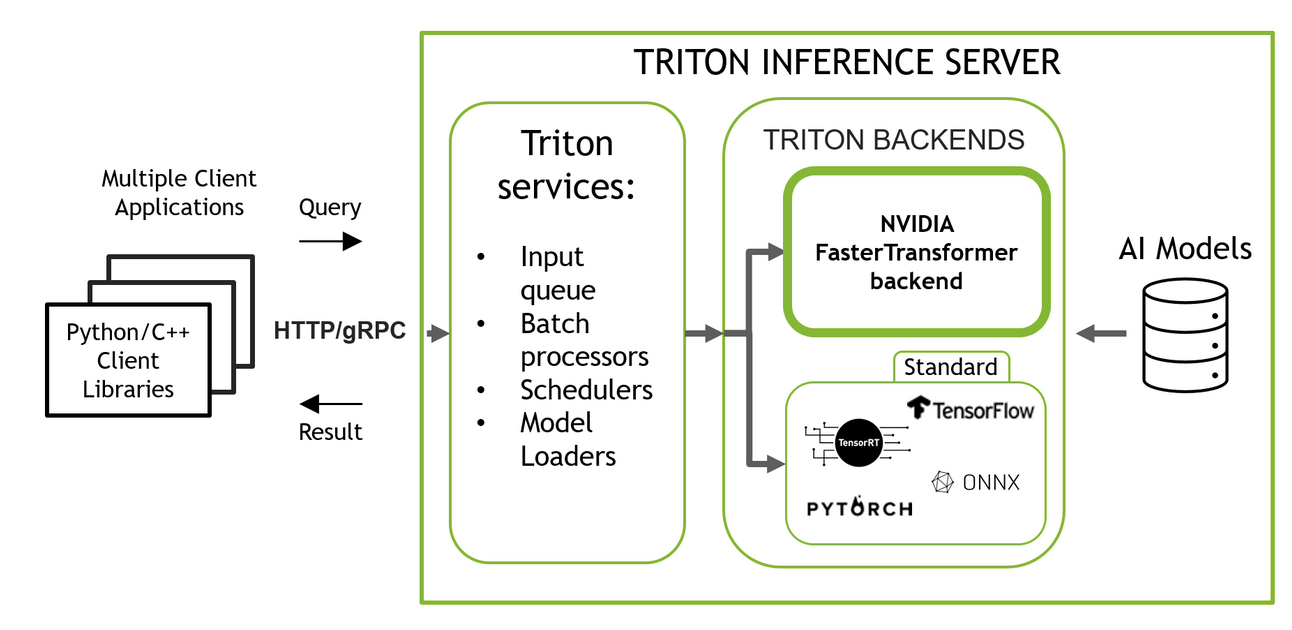
There are a few languages / options we can utilize with different pros / cons:
- Python is the usual choice, but it doesn't work well for true parallel processing. It can cover I/O bound applications via AsyncIO, but has a poor environment for utilizing all CPU / GPU for a model outside of the
multiprocessingmodule- Main thread would need to do all of the batching, I/O, scheduling, etc and use multiprocessing on all other cores to spin up models and have them run actual inference
- Rust is the most performant, but is (in my personal opinion) quite possibly the most disgusting language in the world to work in. It has true parallelism capabilities, and great request / response patterns along with saturating all CPU / GPU on a machine
- Go is easier to work in than Rust, but less performant
- Java is easier to work in than Rust, but less performant
- Rust, Java, and Go all have some form of native support for Tensorflow, PyTorch, etc based models for serving, but there would need to be some pre-processing that's completed or the model may need to change to be serialized into these languages as Python dumping out a
pickle.dump(model_weights)may not be 100% supported in each language- Furthermore the pre-processing of inputs may need to change for each of these languages to support proper data types
- All of these languages have true I/O bound + parallelism for CPU bound work, and scheduling models on cores and tying them to different abstract processed with proper communication channels
Low Latency Monolith Deployment
The best setup for low latency ( 40ms) inference with concurrency will start with a monolith split up between an orchestration process (Go, Python, etc) and GPU based inference processes (C++, Python calling C++) where inter-process communication (IPC) happens via gRPC or low level sockets / pipes. For this example we'll stick with Python as the AsyncI/O framework, and C++ as the inference process that interacts with NVIDIA A100 GPU's on a device
We'll host BART-large on each GPU which requires:
- 413 MB of VRAM to load in float16 precision for inference
- For transformer models in
fp16(half-precision), you typically need 2GB of VRAM per 1 billion parameters for weights alone - Add 20% on top for activations, framework overhead, etc
- For transformer models in
Triton is a good example of how all of this would actually look if we wrote out C++ code to interact with GPU's, and created some sort of client API to send requests, and had a C handler API to actually interact with backend processing - it's very complicated
Triton Walkthrough For gRPC
The actual gRPC API that handles accepting new inference calls can be modeled after the Triton example:
- gRPC New Request
- That
RequestModelInfercall is the async-server pattern in gRPC C++: it requests that gRPC match an incomingModelInferRPC to this state and enqueue an event on the completion queue (cq_) when it arrivesRequestModelInfereventually comes through as "gRPC runtime, please notify me (via the completion queue) when the nextModelInfercall arrives, and bind it to this state object"- i.e., when you accept one client request, you must re-arm yourself for future requests. So it's a continuous "I received this one, send me more"
- In gRPC async C++ servers, “accepting” an RPC is not implicit and doesn't release unless you keep posting receives
- That
- gRPC Process Request
- When a request has
step.STARTit will- start a new request
StartNewRequestwhich posts anotherservice_->RequestModelInfer(...)so the server is ready for the next incoming call - Runs
Execute()to process the current state
- start a new request
- When a request has
- Processing a request is eventually done by
TRITONSERVER_ServerInferAsyncwhich is the C API entry point that submits an inference request to the Triton core for asynchronous execution- This will immediately return (if Triton Core accepts it), and then the results come back later on via callbacks that were registered in
TRITONSERVER_InferenceRequest - Triton then creates
TRITONSERVER_InferenceResponseand delivers them via response callback - The response allocators are how Triton knows where, how, and what to send back and the structure of the actual response buffer
- This will immediately return (if Triton Core accepts it), and then the results come back later on via callbacks that were registered in
Actual inference is then handled in Triton Core Repo
- The Dynamic Batch Scheduler covers dynamic batching of new gRPC requests
- This will create and enqueue a request
- Potentially do a cache lookup if enabled
- If not dynamic batching, immediately send the request
- Otherwise add to batcher, enqueue it into schedulers internal priority queue, decide to wake up batching thread, and if woken up start the actual call with
cv_notify
- This will create and enqueue a request
- Every new gRPC request becomes an
InferenceRequest, and is added to the scheduler viaEnqueue() - In Dynamic Batching, there's a new thread created if it doesn't exist
- The thread itself runs the
BatcherThreadmethod- This creates payloads
- Waits for Execution PayloadSlots
- Also waits for GetDynamicBatch() to return
- This walks over the enqueue'd requests
- Ensures it's not larger than
max_batch_request_size - Returns
0when it's finally ready to send a pre-set batch size- If 0, constructs a
curr_payload - Continuously dequeue's these requests
- If 0, constructs a
- Eventually, it'll finally enqueue a payload to the model!
- The thread itself runs the
Low Latency Monolith Realistically
Given no one wants to write any of the above code ever again, the best bet is to write clients that utilize an open source serving framework for the actual inference runtimes
- Triton is great for true low latency, high concurrency, parallel inference that works on NVIDIA GPU's, or any CPU
- Can serve any model with custom configs, and has pre-sets for ONNX, Tensorflow, PyTorch, etc
- This specifically allows for multi-GPU clusters
- Ray Serve is a useful framework for distributed processing, potentially semi real-time, but more useful for non real-time scenario's that need distributed compute and processing
- Pipelines, reinforcement learning, enqueue'd distributed serving ( 1s), etc
- Work with both GPU or CPU workers
- Tensorflow Serve is useful for Tensorflow only, and somewhere inbetween Triton and Ray Serve