10. Dynamic Programming
Dynamic Programming
Why Dynamic Programming?
When a question asks us to minimize, maximize, or find the number of ways to do something, it doesn't always mean that dynamic programming is the best approach, but it is usually a good indicator that you should at least consider using a dynamic programming approach
Dynamic programming is useful if a problem has following characteristics:
- Overlapping Subproblems which just means smaller versions of the original problem are re-used multiple times
- Overlapping in the sense that "smaller" versions of the subproblem's answers are reused many times again to solve further downstream problems
- Optimal Substructure means an optimal solution can be formed from optimal solutions to overlapping subproblems of the original problem
- Any can be formed from solutions to subproblems , and this solution is the optimal solution
Divide and conquer has an optimal substructure where solutions are formed from subproblems, but these subproblems never overlap - you compute them once and merge everything together and it's done!
Typically, DP problems are framed as finding the maximum or minimum of something - this question framing also shows up in binary search and sliding windows. Binary search is best used when we can split the solution space greedily, and sliding windows are best used on monotonic sliding windows, however neither of these are best solved by utilizing sub-problems results to find the optimal answer for the current solution. A second characteristic which covers this, is that future "decisions" specifically depend on earlier decisions - if you find that the decision made upstream affects what decision you'd make here, it's often a DP problem
The best example is the house robber problem, where a robber wants to rob a set of houses, but cannot rob adjacent houses due to security alarms. If the houses were [100, 50, 400, 200, 100] the optimal route would be 0 --> 2 --> 4 which is fairly straightforward, but if it was [400, 100, 100, 600], the optimal route would be 0 --> 3 which shows that no greedy solution would solve this. If we just did best of last 1 or 2, we'd miss out because earlier decisions would ruin the optimal route
So what is the optimal route? At any step , you would want to find the maximum based on all houses , which is inclusive of every decision except for any that includes the immediately adjacent house
Show Python Script
class Solution:
def rob(self, nums: List[int]) -> int:
n = len(nums)
if n <= 2:
return(max(nums))
dp = [0] * n
dp[0], dp[1], dp[2] = nums[0], nums[1], nums[0] + nums[2]
for houseIdx in range(3, n):
dp[houseIdx] = nums[houseIdx] + max(dp[houseIdx - 2], dp[houseIdx - 3])
return(max(dp[n - 1], dp[n - 2]))
The longest increasing subsequence problem shows a relatively straightforward DP example, and then the section below on using Binary Search to reduce it from to is a good way to show just how completely screwed some of these problems can be
Next to this, the longest consecutive subsequence problem is a hash set + greedy loop problem!
Top-Down vs Bottom-Up
Top-down is known as memoization
Bottom-up is known as tabulation
They are both used to solve DP problems, but most problems make more sense one way or the other - similar to how BFS and DFS can both be used in graphs, but one usually makes more sense than the other
Bottom-Up (Tabulation)
Bottom-up isimplemented with iteration and starts at the base cases, typically something like (0, 0). In the fibonacci sequence problem, we start with dp[0], dp[1] = 0, 1 and calculate everything from there
Show Python Script
def fibonacci(self, n):
dp = [0] * (n + 1)
dp[0], dp[1] = 0, 1
for i in range(2, n+1):
dp[i] = dp[i-1] + dp[i-2]
return(dp[n])
Bottom-up is based on iteration, typically in a for loop, which is much easier to understand than other recursive based techniques. It often involves a 1-D or 2-D array to track states, and will start as a base case (0, 0) to move forwards
Top-Down (Memoization)
Top-down is basically the reverse, you start with the end result, and work downwards until you reach the base case, storing intermediate calculations for future lookup in a hashmap or other data structure
In the fibonacci example, you'd start with f(N) = f(N-1) + f(N-2) and work downwards until you reach the f(0), f(1) base cases. In the middle there are multiple times you'd calculate f(2), and so memoization ensures that lookup is by storing the calculation output somewhere
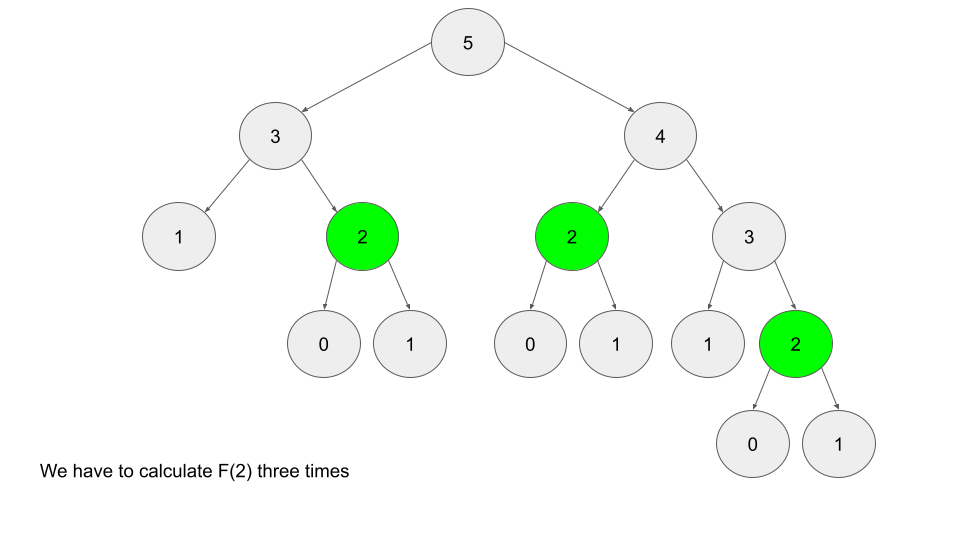
The actual storage of f(2) in an data structure for future access is what's known as memoization
Show Python Script
class fibonacci:
def __init__(self):
self.memo = {}
def fib(self, n):
if n == 0 or n == 1:
return(n)
if n not in self.memo:
self.memo[n] = self.fib(n-1) + self.fib(n-2)
return(self.memo[n])
Comparison
So which is better?
Any DP algo can be implemented with either method, but typically one is "better" than the other in the same way BFS is "better" than DFS in certain situations, and vice versa
- Iteration is usually faster than recursion, and easier to work through mentally compared to recursion
- Memoized recursive results are usually easier to write, because the actual ordering of the problem doesn't matter
- In tabulation you have to ensure the subproblems are solved beforehand, in memoization you just calculate and the results eventually get cached whenever they need to
Memoization requires large space complexities for call stack, and also must duplicate variables, ensure scope, etc so it's definitely extra work on the compiler / interpreter. At large enough scale this can introduce real bottlenecks
Dynamic Programming Solution Structure
The state defines a set of variables that can sufficiently describe a scenario, and these are known as state variables. Most of the time it's a current sum, length, size, etc. For each step in a DP solution, most of the time for a specific index i, we define a unique state of index i
There should be a function / data structure to contain, and also help us compute, answers for each state. Typically this is stored in a 1-D or 2-D array dp = []. These functions answers must be based on previous sub-problems answers, and the answers must be the optimal one at each state - this ensures the DP paradigm is appropriate for the problem, and this idea is the recurrence relation that shows how we transition between states. Usually this takes the form:
Where afterwards, we can store the base cases in dp, and reuse them over time
Setup:
- A function / array that represents the answer to the problem from a given state
- This is typically called
dpin any problem
- This is typically called
- A function / relation to transition between states
- Getting from
dp[i]todp[i + 1]or vice versa - This is typically the hardest part to find in any DP problem
- Getting from
- A base case!
- Starting at
dp[0](front) ordp[len(input)](back) is typicaly the easiest to start with
- Starting at
Subsequences
One of the most common use cases is subsequence problems
Why this makes sense is because at any point you can "drag along" info from previous subsequences
Substrings must be contiguous, but since subsequences aren't there are times you may want to compare two different subsequences - that is typically done in the dynamic programming 2D chart arrangement
This Leetcode solution showcases the below setup
- String A:
abcde - String B:
acfe - Matrix of rows and columns for and
- If a cell has , meaning the row and column letters are equal, then you take the last diagonal and add 1 to it
- This corresponds to "given our last longest subsequence, you found another entry for it"
- If the cells do not match you need to take the and just bring along the last largest subsequence we've found
Table:
| a | c | f | e | ||
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | |
| a | 0 | 1 | 1 | 1 | 1 |
| b | 0 | 1 | 1 | 1 | 1 |
| c | 0 | 1 | 2 | 2 | 2 |
| d | 0 | 1 | 2 | 2 | 2 |
| e | 0 | 1 | 2 | 2 | 3 |
The Longest Increasing Subsequence is another good problem showcasing subsequences and dp recurrence relations. In this there's even a way to use binary search to make it