Rebalancing Protocol
Rebalancing
The Stream Processing document covers processing, consumer groups, partitioning, and other topics - in most of these discussions it mentioned "rebalancing", but didn't get into the nitty gritty
Utilized a few good resources like this Rebalancing Protocol Medium Article, and some of the Confluent documentation
Remember that the unit of parallelism in Kafka is the partition - each topic has one or many partitions, and the stream tasks for consumer clients will process these partitions. These stream tasks are exactly 1:1 with partitions, so if there are 20 partitions there are 20 tasks running on our consumer cluster of instances. Each stream task is apart of a consumer group, and Kafka guarantees that a topic partition is only assigned to one consumer (instance) within a group that will run a stream task over it. The number of active consumers in a consumer group, and their available CPU resources, determines the number of stream tasks they can run and process in parallel - if there are 20 partitions and our consumer group only has 10 active consumers with 1 CPU each, then each active consumer will (most likely) be assigned 2 partitions, thus 2 stream tasks:
- Each partition is always assigned to only one consumer instance within the group
- If there are more partitions than consumers, each consumer will process multiple partitions in parallel (as many as its resources allow)
- If a consumer instance has only one CPU, it will run both stream tasks on that single CPU, which may impact performance, but it is allowed
These stream tasks can run stream 2 stream operations which are simple, or they can create stateful tables - altering which data is sent to which stream task is known as rebalancing, and it helps with scalability, but it changes what data a certain consumer sees which comes with lots of edge cases to cover
In the example below there are 4 partitions and 3 active consumers in the A Consumer Group
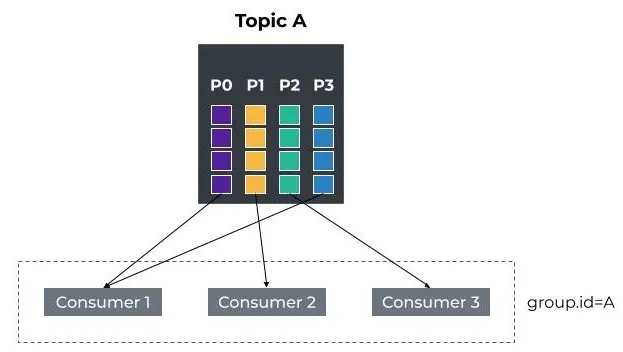
If a consumer needs to leave, or more consumers join, the partition function and the allocation of which active consumers handle which partitions will change, and this is the purpose of rebelancing - it allows for scaling
Rebalance Protocol
To start the discussion, there's a proper definition of rebalancing:
Rebalance/Rebalancing: the procedure that is followed by a number of distributed processes that use Kafka clients and/or the Kafka coordinator to form a common group and distribute a set of resources among the members of the group (source : Incremental Cooperative Rebalancing: Support and Policies)
The above definition also covers many things outside of producers and consumers, so it's a bit vague - it's usage can cover:
- Confluent Schema Registry: Relies on rebalancing to elect a leader node among it's total cluster of nodes
- Kafka Connect: Uses it to distribute tasks and connectors among workers
- This is used to integrate Kafka into other 3rd party systems, and it runs as a separate service
- ETL, CDC, etc
- Kafka Streams: This client processing application code uses it to assign tasks and partitions to application stream instances
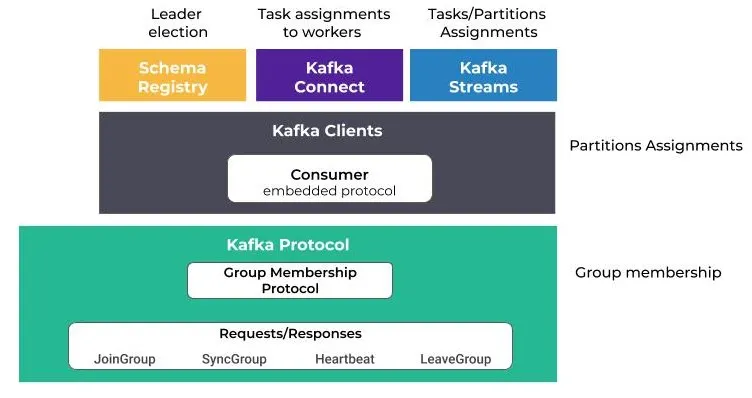
Most of the above is handled by 2 main protocols:
- Group Membership Protocol: In charge of the coordination of members within a group. Clients participating in a group will execute a sequence of request / response exchanges with a Kafka broker that acts as it's coordinator
- This is the basic coordination mechanism between clients (consumer applications) and the Kafka broker that acts as it's coordinator
- Client Embedded Protocol: A customizable part of the protocol that runs in side of client instances. Allows clients ability to define how resources like topic partitions are assigned to group members (i.e. the consumer instances)
- This is just a specific implementation / configuration of the Group Membership Protocol, one that is specific to client instances and applications
Some of the vocabulary used above is similar to what was used in the RAFT Consensus Algorithm, and although they ultimately serve different purposes most of the edge cases and implementation oddities are the same
- Both involve heavy coordination among distributed nodes that all have a "dumb" thought process
- These "dumb" thought processes, when aggregated and combined over many nodes, produce intellectual and coordinated results
- This doesn't require communication paths among all nodes, they all typically work with a central coordinator of some sort
- Both use leader election and coordination to manage distributed state and ensure consistency
- Both handle changes in cluster membership (joining, leaving, heartbeat, OOM, etc) and redistribute responsibilities accordingly
JoinGroup
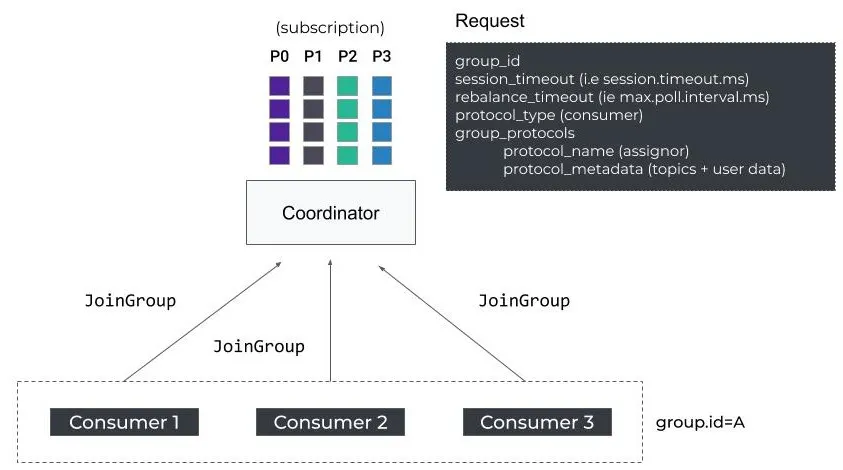
When a new consumer starts it needs to do a few things:
FindCoordinatorwill send a request out to obtain the Kafka broker coordinator which is responsible for the group the new instance is trying to join- Once that's done, there'll be a
JoinGrouprequest that's started, and any further work by consumer applications will be met with aRebalanceInProgresserror / notification - Once it's found the
JoinGrouprequest is sent to that coordinator to try and actually joinJoinGroupwill also contain some parameters that the coordinator will use to potentially kick members out of the group if they don't respond within some heartbeat interval -session.timeout.msandmax.poll.interval.ms- There is also metadata included around which list of topics the consumer has subscribed to, and some client protocol information around the partition assignment strategy for consumers
- When a
JoinGrouprequest is sent, the coordinator will create a "barrier" according to the documentation, and waits for all expected consumer instances to also send aJoinGrouprequests. The coordinator doesn't send responses (i.e. finalize group membership and partition assignment) until either:- All active consumer instances have sent their
JoinGrouprequests - The configured timeout
group.initial.rebalance.delay.ms(i.e. rebalance timeout) is reached
- All active consumer instances have sent their
The Rebalance JoinGroup request is initially sent by a new consumer, and that triggers the coordinator to stop all work and start a Rebalance
- The above barrier ensures that all current members have a chance to participate in the rebalance and receive their partition assignments at the same time, and if a consumer instance is too slow the coordinator will proceed after the timeout
- When I first read this it sounded like the coordinator will receive a request from a new node and expect each other active node to also just magically know this and send
JoinGrouprequests, but that's not the case
- When I first read this it sounded like the coordinator will receive a request from a new node and expect each other active node to also just magically know this and send
- Each consumer only sends a
JoinGrouprequest when a rebalance is triggered, and when the new node joins and sends the initialJoinGroupto the coordinator, the coordinator will nitify all existing consumers by sending aRebalanceInProgresserror (in response to their heartbeat or something else)- THIS is something similar to RAFT, where consumers are just sending random 1:1 request responses to the coordinator, and if they get some specific error like
RebalanceInProgress, it does some new logic to continue processing - This seems dumb, but it ensures conistency and consensus in the long run
- During this
RebalanceInProgress"barrier time" no actual processing work is done and the coordinator ensures coordination among all nodes with proper partition assignment
- THIS is something similar to RAFT, where consumers are just sending random 1:1 request responses to the coordinator, and if they get some specific error like
The first consumer to respond to the RebalanceInProgress within the group receives the list of active members and the selected assignment strategy and will act as the group leader while other nodes will receive an empty response. This group leader is then responsible for executing the partitions assignments locally
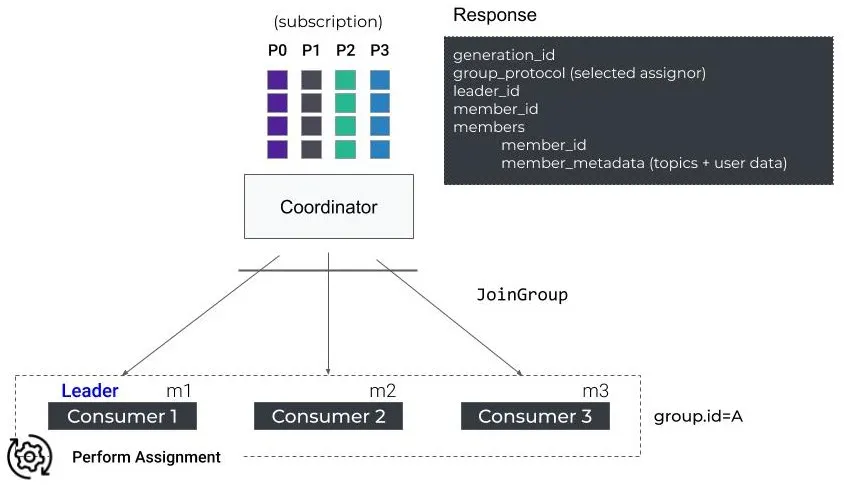
SyncGroup
At this point there's a group leader, and a set of consumers willing to participate and they've been receiving partition assignments from the group leader

SyncGroup is the final step in the rebalance protocol, after all consumers have sent JoinGroup requests, and the group leader has determined the partition assignments, each consumer will send a SyncGroup request to the coordinator
The coordinator will finally respond to each one of these requests to each consumer and send back each of their partition assignments - this brings all requests through the coordinator, has the group leader in sync with all local consumers, and each consumer in sync with group leader
After that, each consumer will implement the theonPartitionsAssignedMethod on the configured listener and then start actually fetching messages
Heartbeat
Throughout the processes above, normal processing, slow periods, and just in general each consumer will send a Heartbeat request to the broker coordinator to keep it's session alive (must be less than the heartbeat.interval.ms)
A Heartbeat is the most common request where a broker will respond with a RebalanceInProgress notification, and that's how consumers start to understand there's other actions for them to take - again, similar to RAFT the broker won't go and tell everyone, it will wait for the consistent Heartbeat request and let them know at that point
The point keep being brought up is that "dumb" request / responses lead to actual coordinated and consensus, and these are all facilitated by understanding there will be constant communication usually via the Heartbeat protocol
In the case where the Heartbeat isn't sent before the heartbeat.interval.ms is reached, it will trigger a rebalance and this consumer will be treated as failed
Caveats
- Stop-the-world-effect: Rebalancing one single instance requires stopping the entire group and stopping all processing
LeaveGroupJoinGroup- Missed
Heartbeat - etc... are all reasons why we need to completely stop all processing
- If we choose our rebalancing / scaling metrics to be "too tight" this will cause constant rebalances
- Scaling optimization metrics are therefore an extremely important topic in cluster configuration
- What happens if the consumer is just restarting from some weird transient error? Well...it'll again send a
JoinGrouprequest and completely set things off!- Consumers are "dumb", they have a finite set of actions, and the request / response based on these actions create a consistent system, and ensuring that things are "dumb" actually reduces operational complexity and makes monitoring easier, but it does have some cons like "dumb rebalancing"
- Static Memberships help in situations like this where newer Kafka versions allow transient failures to not cause rebalances, and if the VM comes back online within some time period it will let the consumer catch back up without triggering a rebalance
- This is useful to stop causing rebalances, but ultimately adds more operations and edge cases for us to debug
- Still needs to be back up within
session.timeout.ms, but the consumer won't send aLeaveGrouprequest when it's stopped anymore - It will just try and restart the consumer application instance binaries, and then when it comes back online it will try and rejoin the group, but the coordinator will return it's cached assignment back to it- This would require new parameters in
JoinGroupthat allow for sending back the cached assignment, and thenJoinGroupwould need to also act as a heartbeat here
- This would require new parameters in
- It's recommended to increase
session.timeout.msif using this static membership configuration
- Upgrades to consumers will cause rebalances - sometimes we need to upgrade VM images and versions, add in new software, take VM's down for maintenance, etc...
- There are "rolling upgrades" available, but if we have 6 instances and we do rolling upgrades of 2+2+2, that means 3 total rebalances that must be done - it may be more efficient to just take all 6 down and replace all 6 with new images
- Incremental Cooperative Rebalancing is a new strategy for solving some of this, it allows for performing rebalancing incrementally in cooperation
- It would execute multiple rebalance rounds rather than a singular global one
- Heartbeats on Java are a common issue because there may be some garbage collection going on that eats up the CPU cycles needed to send
Heartbeatrequests. This is always a typical issue with Java programming, and involves configuring JVM options, Kafka configurations, and strategies between application logic and infrastructure
There are hundreds of other caveats, especially when you start to look into Kafka Connect, Kafka Streams, and other Kafka environment tooling - these all use the Rebalancing Protocol, and so the hundreds of thousands of edge cases that come up would be well beyond this document
These sorts of consesnsus, consistency, and communication systems are typically the hardest parts of distributed systems, and the common thought is to keep things "dumb", which will inherently create smart systems when you aggregate the results. This setup will ensure easier monitoring and observability, while allowing edge cases to be tracked down, but there are lots of event loops, heartbeats, and weird hiccups to overcome with a partitioned system