Kafka
Kafka
Kafka at it's core is a distributed queue with extra bells and whistles that ultimately have it categorized as a distributed broker
It's also slightly linked to PubSub? All of these things are generally linked together!
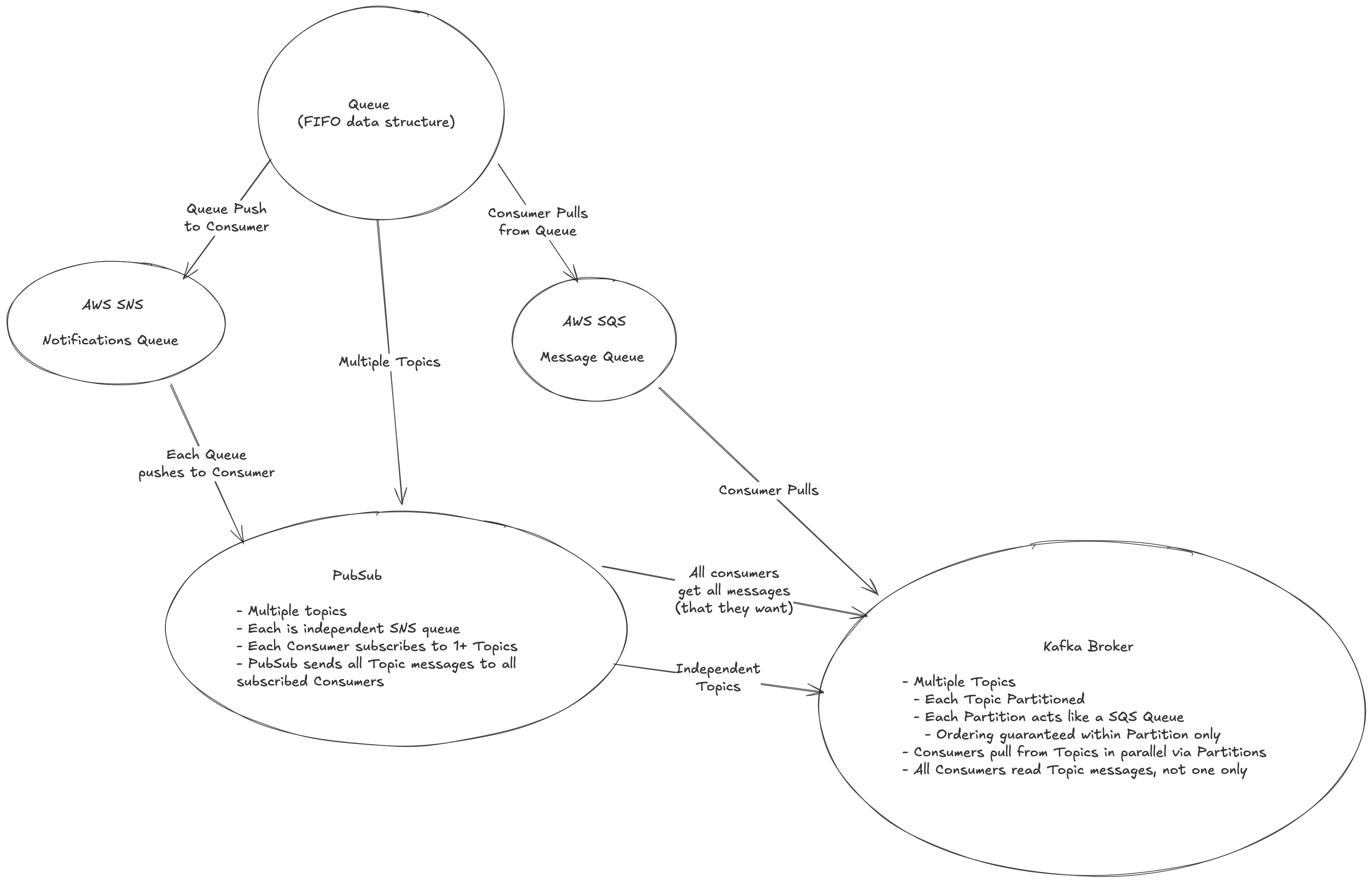
- Queue are FIFO data structures, which Kafka is
- Publishers subscribe
- Consumers will pull a message, and typically the message is pulled by only 1 consumer
- PubSub servers are similar to queue's, but they build on top of them with slightly different semantics
- Publishers still push messages
- There are typically one or more consumers
- Because of this, the PubSub server is usually responsible for pushing to consumers instead of consumers pulling like in a queue
- Some PubSub servers allow for consumers to pull, and at that point they're similar to multi-consumer queue's
- Kafka itself will have topics, similar to PubSub, except each topic is further split into partitions
- These partitions act as SQS message queue's where consumers will pull off them, but they deviate from message queue's in that each consumer will access each message 1+ times. Kafka doesn't host each message only once like SQS message queue's do
- Ordering is guaranteed within a partition, but not in a topic
- Routing to partitions is an important thought topic, as incorrect routing or partitioning can lead to bad aggregations on the other side if order matters
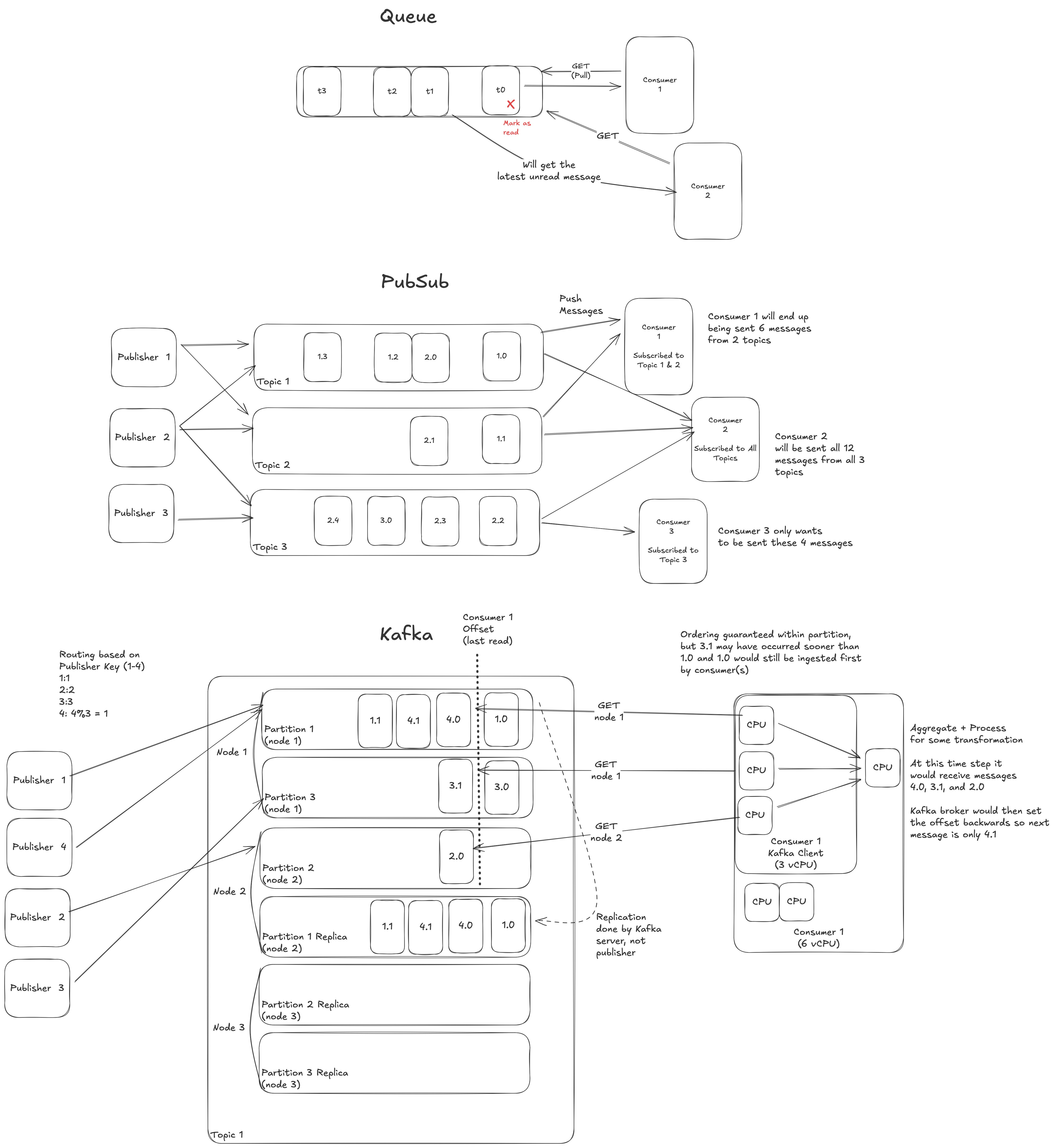
Kafka Architecture
Kafka is built up on independent SQS brokers as partitions, and partitions are separate buckets of a specific topic, and topics are generally what Producers and Consumers work with
At a high level this is simple, but working through different use cases starts to show where the actual implementation details matter:
- Schemas and Serialization
- Scaling and Partitioning
- Heavily drawing on rebalancing, which is covered in Rebalancing SubDocument
- Durability and Fault Tolerance
- Streams, Tables, Offsets, and Aggregations
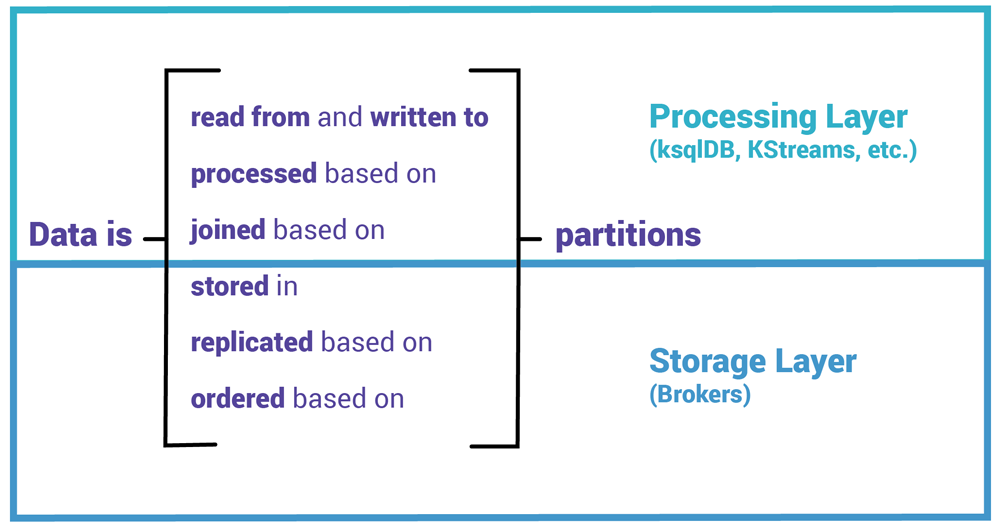
Storage Fundamentals
Topics are the most well known concepts, and they're where Events are durably stored for as long as necessary - they're similar to a distributed file system of append only events. A topic is an unbounded sequence of serialized (bytes) events, where each event is simply represented as an encoded (bytes) K:V pair (Message). These Messages have metadata associated with them like timestamps, schema information, etc, but that's separate from the conversation - topics only see raw byte arrays, and they handle these Messages in a "dumb" manner, so they scale easily! topics can store data for a set period (3 days), a set size (3 GB), indefinitely, or based on other metrics.
Serialization happens on read and write - this is how Schema's are enforced, and how producers and consumers keep contracts with each other. The servers that handle storage of topics are "stupid", so they only handle bytes, but both producers and consumers need to have some sort of schema so that know how to encode (serialize) and decode (deserialize) these bytes - similar to how L7 HTTP API's need to handle L4 bytes being sent to them from the TCP layer. These serialization operations are handled entirely by Kafka Clients (producers and consumers) like kSQL, Kafka Streams, or some microservice using Kafka SDK. These serialization formats are typically handled using Apache Avro, Protobuf, JSON, or some other schema registry and definition framework.
As we stated above, Kafka Brokers only seeing raw bytes makes them "dumb", but they can scale much better - any new node in the cluster simply wakes up and can start being processing new Messages for a topic. The quote from the main Confluent Blog this article is based off of really sums it up:
In event streaming and similar distributed data processing systems, lots of CPU cycles are spent on mere serialization/deserialization of data. If you ever had to paint a room, you may have experienced that the preparation (moving furniture, protecting the floor with drop cloths, convincing your significant other that olive green is doubtlessly a more suitable color than that horrible yellow, etc.) can consume more time than the actual painting. Fortunately, brokers don’t need to deal with any of that!
Partitions are actually the fundamental unit of scalability in Kafka, Messages are the fundamental unit of storage, and Messages are guaranteed to be ordered inside of topic partitions. Partitions are how topics get spread across buckets on different broker nodes - a single topic may be spread across 10-20 actual underlying compute nodes, and this is important for scalability because it allows multiple producers and consumers to write to a topic truly in parallel - if it was one single node, it would be forced to be concurrent. When a topic is created, the number of underlying partitions must be chosen, and then each partition hosts a specific subset of the full topic's data - these partitions are further replicated across other nodes for fault tolerance. Partitions enable scalability, elasticity, fault tolerance, and parallelism.
So the big question with partitions is Rebalancing - partitions come with partition functions that send events to partitions, and if the total number of partitions changes sometimes Messages can be sent to new partitions which can screw up ordering - this was covered, extensively, in almost every distributed storage component especially the Distributed Key Value Store Partition Section. If there are partitions, and our partition function is based on the modulo operator and message.event.key, then all keys that route to partition 0, with a rebalance, may be sent to partition 1 afterwards.
The default partition function is . This means, in most cases, events (Messages) are spread evenly over partitions in a uniform manner
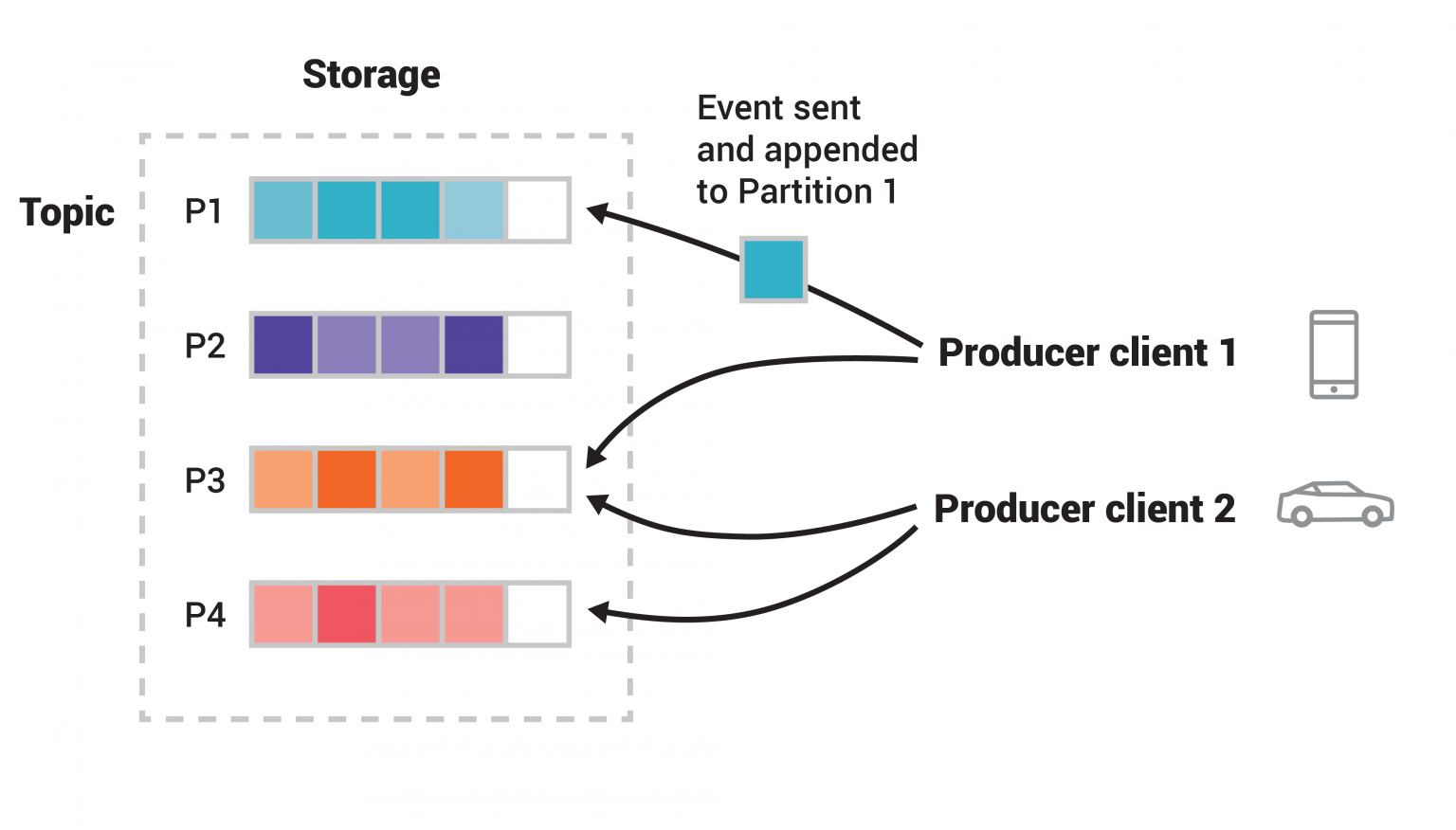
The best way to choose event.key is based on the problem at hand, partitions guarantee ordering, so you want your event.key to lead to correct ordering requirements - the typical example is a truck geo-location service, for this you'd want to use truck_id which would force all location events about the truck to be sent to the same partition, and this would ensure these messages are ordered as they were created (i.e. event_timestamp). If you split up truck information to separate partitions, you may get an unusual ordering like 1,3,2,4,6,5,7 - this is because the 2 partitions aren't perfectly synced. This also ensures that the Kafka Consumer Groups (i.e. the set of consumers) that all read from the same topics are reading data appropriately in parallel, if node 1 consumer handles partition 1 for 1/2 the time, and then node 2 takes over the other 1/2, the Messages will be lost and aggregations that are ran on each node will be incomplete - partition routing ensures all Messages are sent to the same place, they're ordered, and that downstream consumers read them correctly
The general recommendation is to over-partition so that you don't have to rebalance frequently, but this of course doesn't cover the largest use cases of high throughput systems...handling rebalancing will be covered later, as it's an incredibly complex topic
Processing
As data is stored in Kafka, it must be processed! There's an entire sub-document related to Kafka Stream Subprocessing that goes into depth about From Storage To Processing