Feature Store
Feature Store
Feature stores are mostly used in the scenario where you have some set of online aggregations that are used in responding to a users request. It doesn't necessarily need to be used in ML, but it's often used in ML model pipelines where the features are inputs to a model. The main idea behind these feature stores are:
- Offline batch pipelines to calculate large historic features
- Online pipelines to calculate real time features
- Parity between the two
- Time based features to ensure that aggregations are correct
- This is a fairly nuanced point, especially when training new ML models, creating time based features, etc - timestamps are all over feature store data
There are plenty of feature stores that allow for creating the below lambda architecture of online-offline, but the hardest part is ensuring code parity (offline SQL and online SQL are the same), time semantics (rolling features offline are same as online), and orchestration. Without duplicating a bunch of code everywhere with different definitions, most groups turn to open source solutions with declarative formats
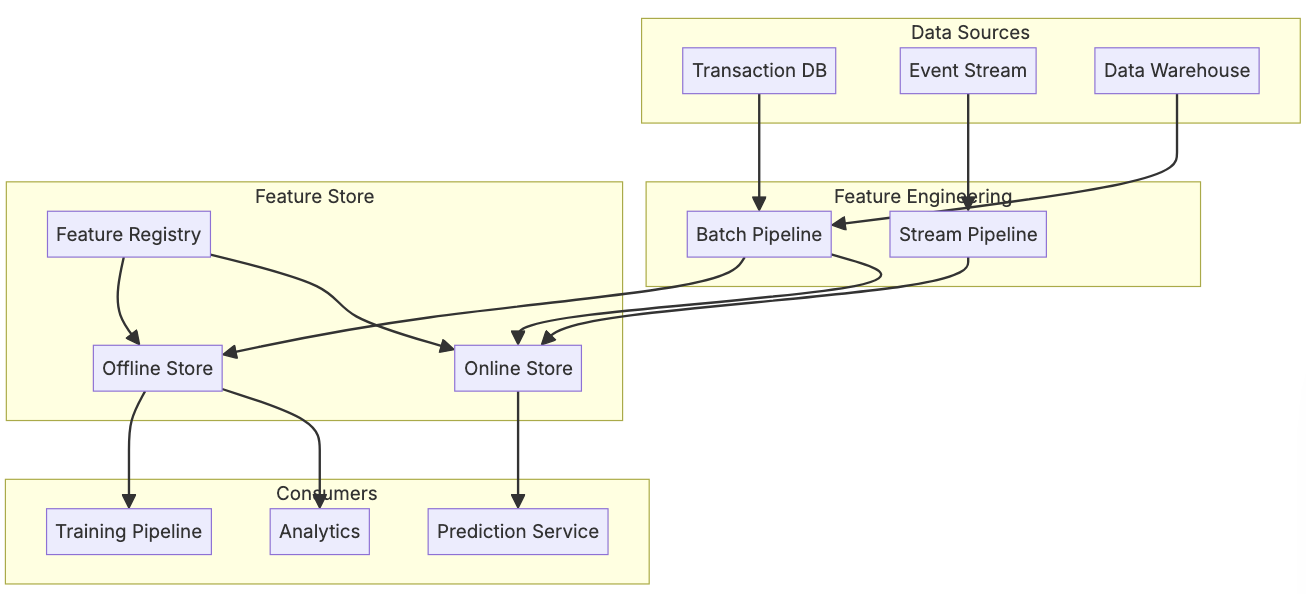
Partity between offline and online is known as online-offline parity, and an extension of that around as-of timestamps is known as training-serving skew, and refers to coming to the same feature calculation results with offline batch processing like Spark and online pipelines in streaming setups like [Flink / Spark Streaming](/docs/architecture_components/messaging/Kafka Broker/STREAM_PROCESSING.md). These are two completely separate systems with two completely separate primitives, and so keeping them in parity is fairly difficult, and adding in timestamps, as-of semantics, and real time serving adds additional complexity that needs to be sorted out
Most feature stores are focused on user-website, user-item, or some sort of user interactions where the features are "clicks in last 5 minutes", "website visits in last 90 days", etc, and these are much harder to keep in check compared to fairly static features like address or yearly spend
In the wild, the typical feature stores used are
- Feast is focused only on serving features in the serving layer, and doesn't look to provide parity in ETL decisions. It needs everything pre-computed to serve
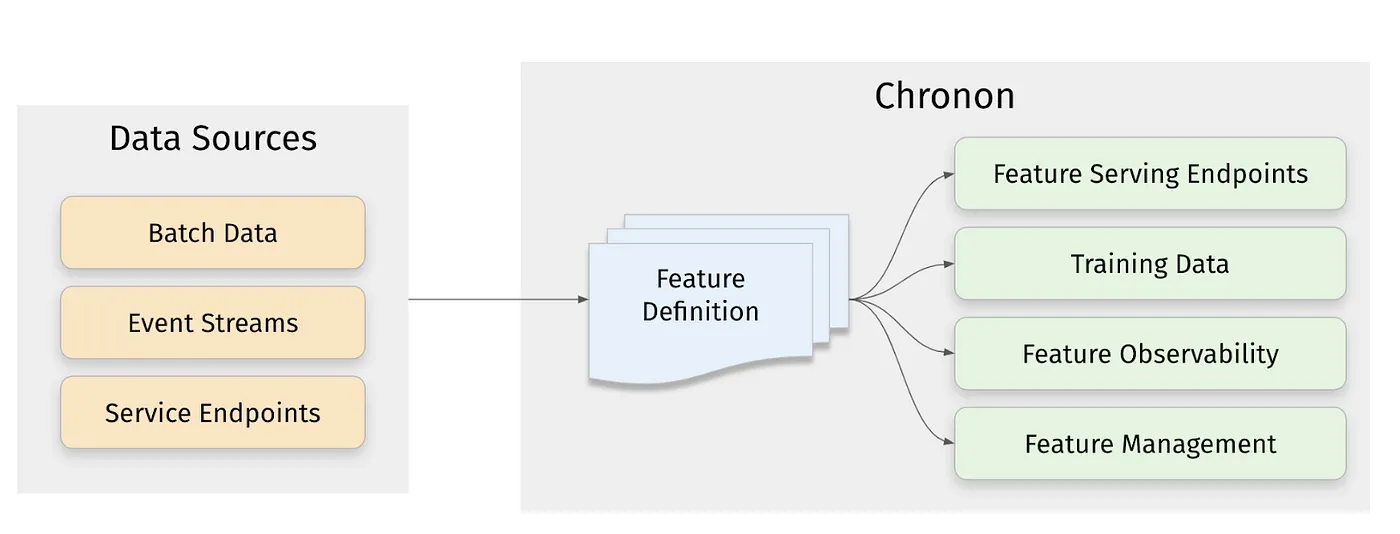
- Chronon is a full fledged feature platform that focuses on automating computation between batch and streaming services. It's tightly integrated with Spark and does well in time-travel joins and offline-online parity / backfilling. It depends on a separate K:V store it can
putandgetto for actual serving- Chronon's life is made much easier by Spark's treatment of streaming as bounded datasets, and so ensuring the same code is used over both online and offline is much more straightforward compared to other [streaming compute engines](/docs/architecture_components/messaging/Kafka Broker/STREAM_PROCESSING.md)
- Chronon is available for Flink too, it does work
- Cloud feature stores like VertexAI and SageMaker integrate with cloud services, and are typically just wrappers around open source projects
Some crazy groups use Chronon for feature ETL, which under the hood runs Spark and [Flink / Spark Streaming](/docs/architecture_components/messaging/Kafka Broker/STREAM_PROCESSING.md) to compute features and ensure parity, and then use Feast for actual serving, but realistically you can get away with just Spark for feature ETL and Feast for serving if you don't have any crazy ETL needs, or Chronon for feature ETL and any K:V store for serving most real-time scenario's
Most of the rest of this is a deep dive into Chronon, which in my opinion is a more important topic to cover in terms of ETL parity compared to serving layers, as once the data is into any sort of distributed K:V store it's basically ready to go as long as hashing and sharding are squared away
Online Vs Offline
The typical scenario is that you have some table of observations, fact data, or something like a user-item table that describes a user watching a movie for example
| user_id | movie_id | timestamp |
|---|---|---|
| 1 | 1 | 00:00 |
| 1 | 2 | 01:20 |
| 2 | 1 | 02:00 |
| 2 | 2 | 02:45 |
Alongside that, let's say your website collects user clicks and user website visits, and in those two real time event sources you end up having some sort of lambda architecture that sinks the events to a data warehouse storing data on disk in parquet, and to an online kafka broker. Let's say the kafka broker is the main pipe inbetween click source and anything downstream. From this, there are many historic aggregations that can be done in your datawarehouse based on timestamps, and your online store can help facilitate small counts like views in last 1 minute. For the features you want to create we can use:
- User’s count of views of items in the last 5 hours - from kafka view event source
- Item’s average rating in the last 90 days - from data warehouse
If views are coming in every second, and ratings are coming in every minute, you can't calculate all of these aggregations per second / minute. At t = 01:30 your rating may be 4.5, and then at t = 1:31 your rating might change to 4.6, and then not get another rating until t = 2:30...so constantly computing all of these aggregations for any time slice would exponentially blow up an underlying data warehouse or database
This is where offline-online feature store parity comes in, for any feature like "average rating over last 90 days" or "user count in last 5 hours" they are inherently time based calculations that need to do aggregations based on timestamp windows over source data, and so ensuring the same actual underlying logic that runs on Spark and [Flink / Spark Streaming](/docs/architecture_components/messaging/Kafka Broker/STREAM_PROCESSING.md) is equivalent is an extremely hard task...the source schemas, the runtimes, the actual underlying ISO SQL language, etc are all different. Offline feature creation is easy via Spark asOfJoins which allow for only pulling data based on some timestamp or partition, but tracking this online is a bit harder to define based on sessions or other time tracking primitives
Produce the view count in the last 5hrs, and average rating in the last 90 days, ending now for a user named Bob
In Chronon, expressing the average rating of an item in the last 90 days computation would come out as
ratings_features = GroupBy(
sources=[
EntitySource(
snapshotTable="item_info.ratings_snapshots_table",
mutationsTable="item_info.ratings_mutations_table",
mutationsTopic="ratings_mutations_topic",
query=query.Query(
selects={
"rating": "CAST(rating as DOUBLE)"
}))
],
keys=["item"],
aggregations=[
Aggregation(
operation=Operation.AVERAGE,
windows=[Window(length=90, timeUnit=TimeUnit.DAYS)])
])
And the number of times the user viewed the item in last 5 hours
view_features = GroupBy(
sources=[
EventSource(
table="user_activity.user_views_table",
topic="user_views_stream",
query=query.Query(
selects={
"view": "if(context['activity_type'] = 'item_view', 1 , 0)",
},
wheres=["user != null"]
))
],
keys=["user", "item"],
aggregations=[
Aggregation(
operation=Operation.COUNT,
windows=[Window(length=5, timeUnit=TimeUnit.HOURS)]),
])
So the reason this works is that there's a common way to express these aggregations that can run over snapshot tables and topics. Bridging the gap between offline and online can be done by utilizing:
- Nightly / cron job offline feature recomputations
- New event source (online) making incremental updates
- Some aggregations cannot be done in an incremental fashion (averages for example)
- These need to be recomputed fully online over windows
The accuracy of a computation, which can be temporal or snapshot, defines whether a computation needs to be online or if it's fine to use the daily refreshes
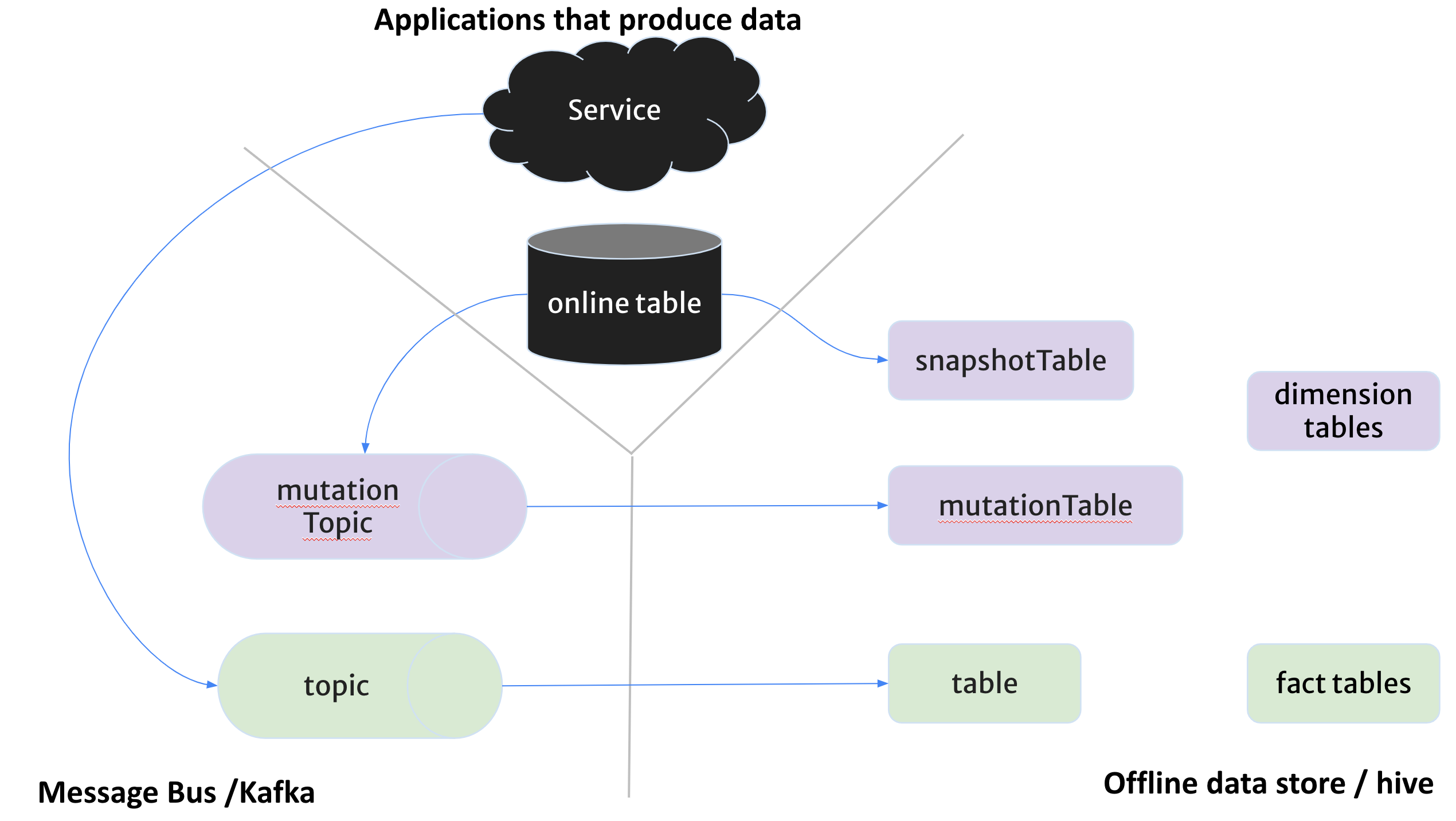
To achieve these two things, Chronon uses Events & Entities objects. The whole point of the storage mechanisms and objects defined below is to ensure that offline nightly refreshes, real time "hot" features, and cumulative online features all have parity and are able to be defined in one singular place, and run on different compute engines for each use case
Events
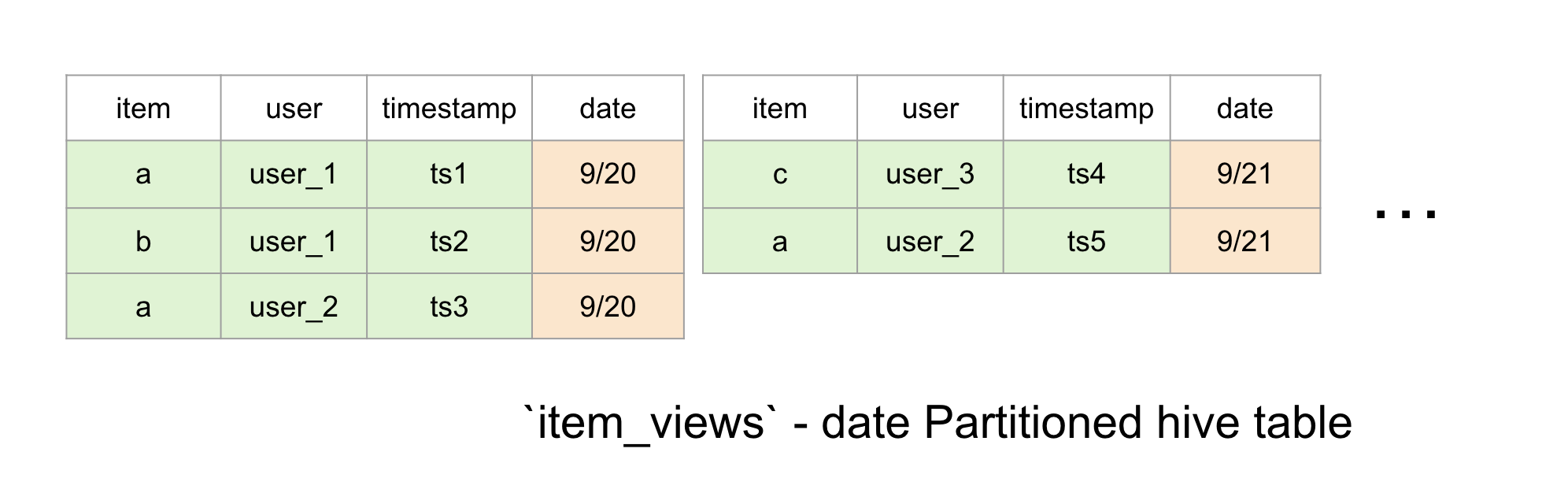
Events are stored as an append only immutable log of events, like views, clicks, transactions, etc. These all have tables and topics:
- Tables are a daily partitioned hive table where each partition contains the events that occur during that day
- Can utilize any
facttable that's derived from some other offline logic as well, but that isn't subject to timeliness-type queries - i.e. if you create a
User <--> Addresstable with SDLC Type 2 slowly changing dimensions, you can store the address per timestamp along with the latest, but ensuring that comes through in a join is difficult without custom logic- This is covered more below in entities
- Can utilize any
- Kafka topic that the events flow through before ending up in hive
- Optional, and is what allows for realtime features
Entities
Entities are a sort of fact table, but ultimately they're a daily / hourly snapshot of some user type database. This is specific to user databases that have daily offloads into Hive, but you could also store users offline in hive and update the storage daily from Kafka events...there are many routes, but ultimately you need to store entities in some hive storage partitioned by some timestamp for timeliness queries. Altogether you can use snapshots + topics to keep fresh online data, and use the same kafka topics to sink into hive to ensure nightly snapshot computations are ran for the following day
Then you can have a mutation topic in Kafka which contains the mutations to the table rows, CDC tools like Debezium are used to update Kafka to ensure parity between online and offline. This pairs with a mutation table which is a daily partitioned hive table containing mutations that heppened in a particular day in each partition. These are only necessary for realtime feature serving and Point In Time Comparison (PITC) backfill, if you don't need these then the snapshot table is able to construct midnight accurate features by itself
Cumulative Event Sources
Slowly changing dimensions Type 2 is a commonly used data modeling technique that works well with append only event sources. The main idea is if you have an append only log of events, you can also keep a record of the value of an entity across time, which allows you to track things like users addresses over time simply from UDPATE rows in an append only log
| user_id | message | cdc_type |
|---|---|---|
| 1 | {'address_name': '100 Main St', 'timestamp': 01} | INSERT |
| 1 | {'address_name': '200 Main St', 'timestamp': 100} | UPDATE |
| 2 | {'address_name': '150 East Road', 'timestamp': 05} | INSERT |
| 2 | {'address_name': 'TOMBSTONE', 'timestamp': 40} | DELETE |
With the above append only log, we can get to a table like:
| user_id | address | timeframe |
|---|---|---|
| 1 | '100 Main St' | 01 - 99 |
| 1 | '200 Main St' | 100 - present |
| 2 | '150 East Road' | 05 - 40 |
| 2 | 'TOMBSTONE' | 41 - present |
The cumulative event source is typically used to capture history of values for SCD Type 2 dimensions. Entries in the underlying database / DWH are only ever inserted and never updated (meaning we don't directly update the value, we create surrogate rows). These are streamed into a live database to potentially be stored with latest values, and also have a sink to the data warehouse using same underlying broker mechanisms as entity sources to reside there long term for future backfilling / analytics
Computation Contexts
Computation is done in 2 contexts, online and offlines, with the same compute definition
- Offline is done over warehouse datasets in hive. These jobs output new datasets, and newly arriving data sits in the warehouse as new partitions
- Online is used to serve application traffic in low latency (
<10 ms) at a high QPS rate, and so Chronon maintains endpoints, backed by K:V stores, that are updated in real time utilizing lambda architecture pipelines
The actual orchestration is done utilizing tooling like Kafka, Spark / Spark Streaming, Hive, Airflow, and K:V stores
Computation Types
To ensure online and offline parity can be guaranteed, all chronon definitions fall into 3 categories:
- GroupBy
- An aggregation primitive similar to SQL with support for windowed and bucketed aggregations. Works for both online and offline contexts in both accuracy models. Will just use keys in both, and a tumbling window of some sort in online queries
- Join
- Simply join data together from various
GroupBycomputations - In online mode a join query is fanned out into queries per
GroupBy. External services and results will be joined together as a map - Offline mode joins are lists of queries computed at a specific point in time
- Joins in offline mode need to treat data "as it was" not "as it is", and so timestamps are of the upmost importance
- Simply join data together from various
- StagingQuery
- Arbitrary computation expressed as Spark SQL query that's computed offline daily
Aggregations
This section focuses on how GroupBy aggregations can be performed in online and offline modes - specifically, how the notion of aggregations can be done over keys. Most of Chronon relies on traditional SQL group-by extensions over keys
- Windows
- Can optionally choose to aggregate only recent data within some window of time
- This is usually used by ML models as features, or by certain application layer features like last-k
- Bucketing
- Specify a second level of aggregation on a bucket, which defines groupings outside of
GroupBykeys - This will output a
Map[bucket_key, agg], so it's essentially a newGroupByover a different key
- Specify a second level of aggregation on a bucket, which defines groupings outside of
- Auto-Unpack
- Unpack nested input data that's stored in an array
- Time Based Aggregation
- This is actually the use case for
first_k,last_k,first,last, etc...I just jumped ahead - It is most likely based on a specific implementation of Window
- This is actually the use case for
Chronon will maintain partial aggregates internally and combine them to produce features at different points-in-time, therefore using huge windows isn't a problem as it essentially creates partitions internally and does aggregations over internal partitions
Orchestrating
There's actually a very nice excalidraw on the Chronon.ai website!
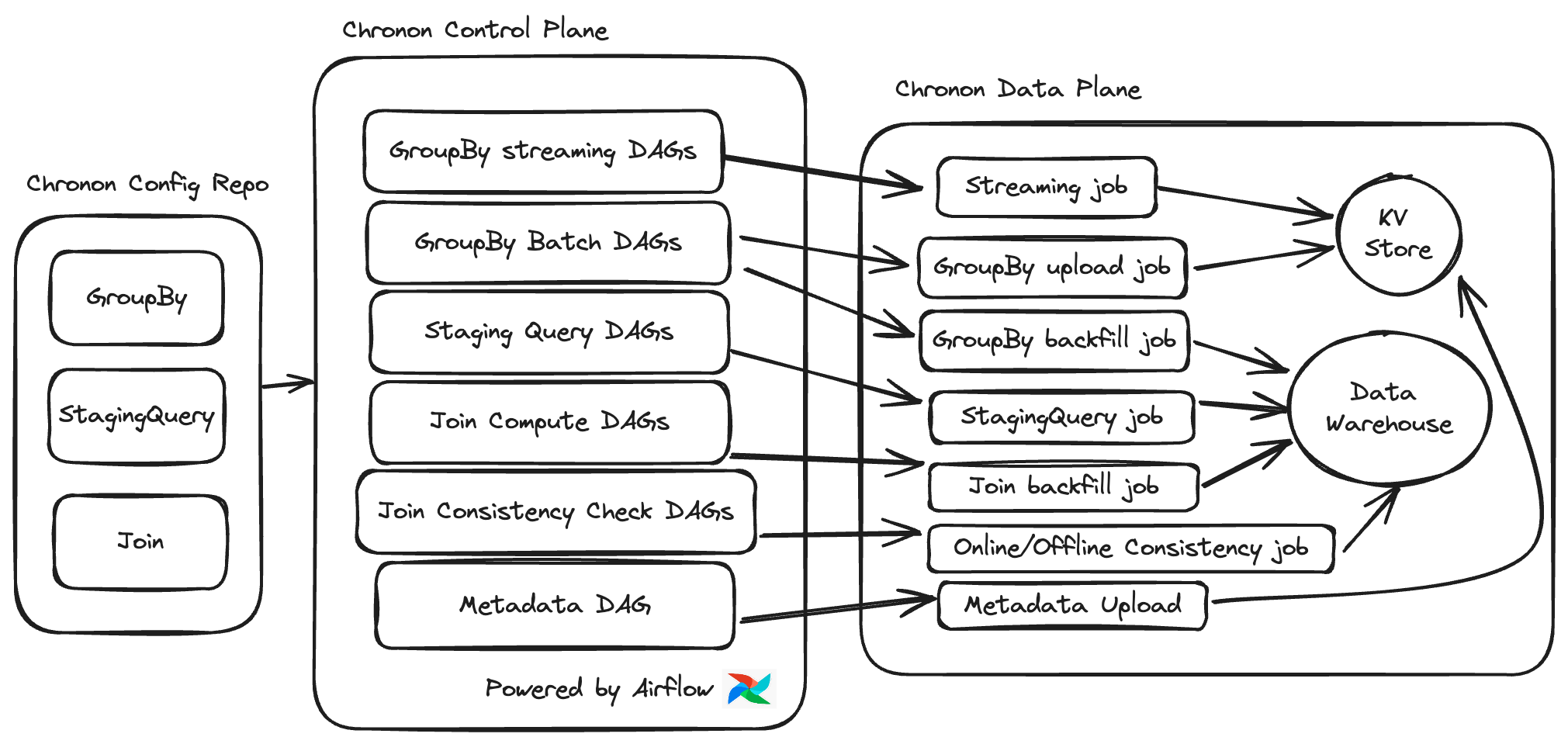
All of the configurations and queries are stored in a repo and deployed to an airflow / some orchestrator instance, and from there all of the actual jobs and joins are deployed on compute engine runtimes. It's very similar to running a "DAG of DAGs" in Airflow, where you setup 4-5 spark jobs to run in Airflow and it sends those jobs to run on Spark executors. In terms of streaming jobs, airflow can submit the SparkStreamingJob to spark and return, but it won't continuously poll the Spark cluster itself. The submit and return pattern, and then checking if exists and exiting in the future, is most likely the best route to ensure all orchestration can live on Airflow without exhausting resources polling a long lived job