Iceberg
Apache Iceberg is a generally more friendly and open source alternative to Delta that can be used by different data engine systems
The Apache Iceberg Spec goes through all of the bits and pieces that make Iceberg, and it's a fair amount of rules and specs that all come together to create the robust system and file format - it reads similar to RAFT and other distributed data systems, and each part is an important part of the puzzle
Delta tables are "tightly" integrated to Spark, and eventually Databricks by way of Spark, and offers ACID transactions via Spark with higher write throughput abilities
It's called Iceberg because it's supposed to work for large scale (iceberg), slow moving (iceberg), analytical datasets! The actual online spec mentions "This is a specification for the Iceberg table format that is designed to manage a large, slow-changing collection of files in a distributed file system or key-value store as a table."
Architecture
Iceberg completes it's goals using certain architecture layers and components that have evolved over different versions - these are all described below
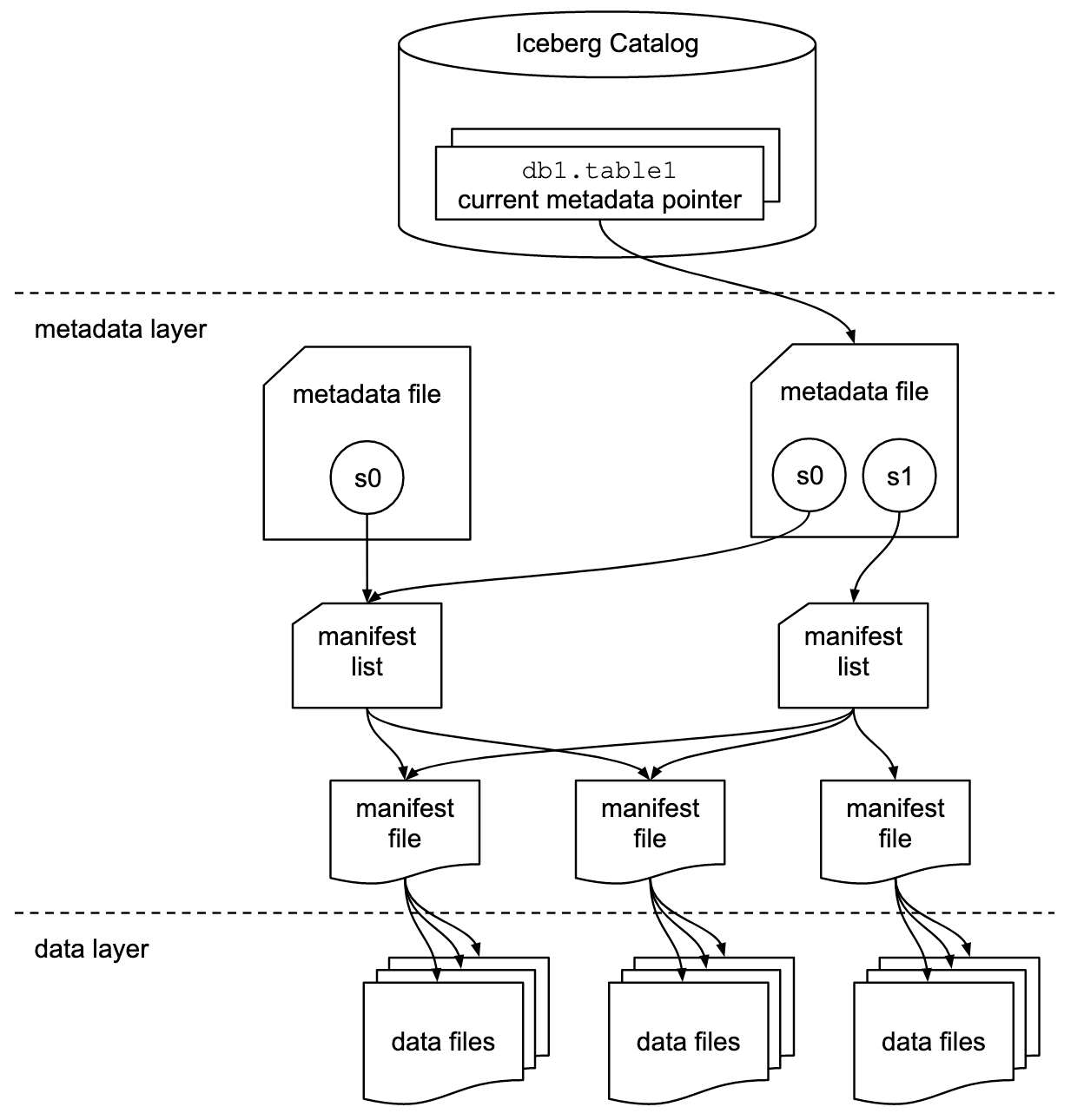
From a high level, the below shows how the different layers in the overall architecture are used to achieve speed and scale goals
Goals
The ultimate goals of Iceberg are to provide some level of isolation, write abilities, speed, scale, and evolving abilities for large scale analytical data systems
In the OLAP community there are always certain requirements for "Big Data" and having scale with distributed compute and storage, and then over time requirements have grown into some sort of ACID compliant structures for consistency
- Serializable Isolation
- Reads are isolated from concurrent writes, and always use a consistent snapshot of data
- Writes will support removing and adding files in a single operation
- Readers never have to acquire locks
- Isolation Level are annoying, but altogether serializable isolation means the transactions appear to have a sequential order
- The only "gotcha" is that transactions are not guaranteed to be executed in the order they were started or committed
- Speed:
- Operations will use remote calls to plan files for scanning
- Mentions explicitly it won't use where grows with the size of the table
- I believe this will be done by using metadata files so that the underlying dataset can grow almost infinitely, but metadata stays in one singular place
- Manifest files, and manifest lists, describe the data files and their locations
- The manifest files are compact and organized so that planning a scan only requires using information in the metadata files instead of going through each file
- Manifest lists point to a set of manifest files
- Each manifest file contains metadata about a subset of data files
- To plan a read / scan Iceberg needs to read list, then read corresponding files, without going through all
- Essentially, it will use some sort of metadata about min, max, first, last, and ordering of different columns to skip and plan file reads
- i.e. it'll use header information, and this header information is updated in metadata files during writes
- Scale:
- No centralized bottleneck
- Job planning handled by clients and not a central metadata store / handler
- Metadata includes info needed for optimizations and planning
- No centralized bottleneck
- Evolution:
- Tables support full schema and partition evolution
- Schema evolution allows column add, drop, reorder, and rename
- Storage Separation:
- Paritioning will be a table configuration
- Ensures tables with different requirements can be handled appropriately
- Reads are planned using predciates on data values and not partition values
- Idk what this means
- Paritioning will be a table configuration
Versions
- Version 1:
- Solely used to manage large scale distributed analytical tables, and specifically focuses on using immutable files stored on disk
- Version 2:
- Adds row level updates and deletes to immutable files
- Does this by including deletion data files that specify what rows are deleted in existing immutable files
- Version 3:
- Adds in new data types, and support for some dynamic structures
- Version 4:
- Not included in current spec
Layers
- Catalog
- A Catalog has many tables
- Individual data files make up a table
-
- Data files are created + updated with explicit transactions
- You add data files to a table with explicit commits
-
- Table state maintained with metadata files
- Metadata
- Data
File Types
Most of the files below end up being used for the Speed goal, and having an plan while also enabling snapshot and point-in-time querying
Manifest lists store which manifest files are apart of a table at any point in time, a table is a union of it's manifest files at the time, and the manifest files track which data files are apart of a table
That's why in the architecture diagram above, you see manifest lists pointing to multiple manifest files as they describe which data files make up a table
- Manifest File
- Track data files inside of a table
- Contain a row for each data file in a table, the files partition data, and metrics / headers about the underlying data
- Manifest List
- Stores information about manifest files
- Helps to do historic / snapshot queries, and stores which manifest files were apart of a table at a specific time
- Each manifest list stores metadata about manifest files!
- Partition stats, data file counts, and ultimately any information to help avoid reading manifests that aren't required for an operation
- Stores information about manifest files
- Metadata File
- Table state is maintained within a metadata file
- Any changes to a table creates a new metadata file, and replaces old one with an atomic swap
- Table metadata file tracks:
- Table schema
- Partitioning configurations
- Custom properties
- Snapshots of the table itself
- Snapshot represents the state of a table at some point in time, and it's used to access the complete set of data files in the table at that point in time
- Data files in snapshots are tracked by manifest files
- Manifest files contain a row for each data file in the table
- Data in a snapshot is the union of all files in it's manifests
- Manifests that make up a snapshot are stored in a manifest list file
- Data File
- Data files store the actual underlying data
- They will use parquet, ORC, avro and other disk based file structures
- Most of these data files are columnar based, and therefore allow operations over columns in a much more efficient format versus rows
- In columnar structures the values in a column are placed next to each other instead of values in a row
Components
These components describe specific patterns / components that help ensure the goals above
Optimistic Concurrency
Atomic swaps of metadata files for tables is how serializable isolation is achieved
Basically, when a reader looks for data is uses a snapshot that was current when it loads the table, and so as a write updates the tables metadata files it will atomically swap these files in and out - this ensures readers aren't affected by changes until it refreshes new metadata
Writers create table metadata files optimistically, which means they assume the current version won't be changed before they write their commits. Once a writer has created an unpage, it commits it's known write by swapping tables metadata file pointer from the base to the new version
So if the base snapshot / pointer is no longer current (another write has updated things in meantime), the writer must retry the update using the new current version - this is what you mean by serializable, sequential updates, but they may not be in the exact order each one was executed / committed. There are some well-defined conditions where you can change some metadata and retry, but ultimately you must retry the entire commit from new base pointer.
Can alter the isolation level by altering the writer's write requirements - serializable isolation isn't strictly enforced. This showcases how a writers requirements, which isn't bottlenecked in by central metadata handler, can determine isolation level of the entire system
Sequence Numbers
Every successful commit receives a sequence number
Therefore, we're able to tell the relative age of data and delete files. As a snapshot is created for a commit, it's optimistically assigned the next sequence number and is written to the snapshot's metadata. Basically, you can follow the sequence (serialized) chain of events that optimistically commit via their sequence numbers.
If a commit fails and has to be retried the sequence number is reassigned and written to a new snapshot metadata
Every single file, manifests, data, and deletion, for a singular snapshot will inherit the snapshot's sequence number. The manifest file metadata in manifest list will also include it's sequence number which helps in historic querying of versions / snapshots - you include manifests in the union via sequence numbers.
New data and metadata file entries are written with null in place of sequence number, and it's replaced with manifests sequence number at read time
When new data is written to a new manifest the inherited sequence number is written to ensure it doesn't change after it's inherited. This inheritance allows writing a new manifest once and reusing it in commit retries, and then changing a number for a retry means only a manifest list must be re-written. All of this inheritance is to ensure there aren't multiple write fanouts that aren't necessary, and only tweaking metadata and sequence numbers would be needed for retries.
Row Level Deletes
These are stored in delete files, which are also immutable files
- Position Deletes will mark a row deleted by data file path and row position
- i.e. filepath
/path/to/dat1.datwith location256 - Position deletes are encoded in position delete file in V2, or deletion vectors in v3
- i.e. filepath
- Equality Deletes mark a row deleted by one or more columns (some sort of identifier)
id = 5means and row with that ID is deleted in subsequent reads
Deletion files are also tracked by partitions as well, and a deletion file must be applied to older data files within the same partition and this is determined and planned in Scan Planning
File System Operations
Iceberg only requires file systems to support:
- In-Place Writes: Files aren't moved or altered once they're written
- Seekable Reads: Data file formats require seek support
- Deletes: Tables delete files that are no longer used
And these are compatible with most BLOB storage systems like S3 and GCS
Tables don't require random write access, once a table is written, all of it's files are immutable until deleted - therefore there's no need for any sort of random write over the files!
Scan Planning
Specifications and Vocabulary
- Schema: Names and types of fields in a table
- Partition Spec: A definition of how partition values are derived from data fields
- Forcing partition by
id, address, phone
- Forcing partition by
- Snapshot: The state of a table at some point in time, including the set of all data files
- Manifest List: A file that lists manifest files; One per snapshot
- This describes the metadata of manifest files, who in turn describe the mettadata of a table, which are all used in Scan Planning
- Manifest: A file that lists data or delete files, and it's a subset of a snapshot
- Helps to describe a table at a specific snapshot
- Data File: A file that contains actual rows of a table
- Delete File: A file that encodes rows of a table that are deleted by position or data values
- Positional (position) vs Equality (value) deletes
Final Thoughts
The rest of the Apache Iceberg Spec goes into Paritioning, Schema Evolution, Snapshots, Metadata, Retries, Commits, Conflict Resolution, and Deletes
It's a very well thought out and well written spec, that helps to define all the typical issues and how to solve them in distributed big data systems
Combining this with tools like Delta Sharing can allow you to have a perfected OLAP system that you use in Data Mesh, Client Sharing, and Analytics