BTree
Anyone who has used CREATE INDEX on Postgres, MySQL, etc has most likely utilized a B-Tree! They are a way to keep an ordered tree data structure on disk, and they are self-balancing!
- B-Trees are self-balancing tree data structures that maintain sorted data and allow efficient operations like:
- Point Lookups: time complexity
- Range Queries: , where is the number of matching results
- Go and find the lower range, and then move offsets beyond to get the range!
Let’s assume we have to store a tremendous amount of data in a computer system. In this common situation, we're definitely unable to store the whole data in the main memory (RAM), and most of the data should be kept on disks. We also know that the secondary storage (various types of disks) is much slower than RAM. So, when we have to retrieve the data from the secondary storage, we need optimized algorithms to reduce the number of disk access. The main idea is that we can do insertion, deletion, and range / point queries with data that's on disk, which allows us to power multiple services like distributed priority queue's, schedulers, and simple items like quick range lookups, or timestamp lookups. Furthermore, there's indexes of indexes (manifests of manifests) which store ordered lookups of offsets - in this the BTree data structure looks to minimize the number of disk accesses needed, all the while keeping things balanced and sorted
BTree Properties:
- Root Node has between 2 and children
- Internal Nodes has between and children, both ends inclusive
- Each internal node may contain up to keys
- Keys don't contain direct pointers, the "range between keys" does
- Leaf Nodes are all on the same level, and each leaf node stores between and keys
- The height can be yielded via
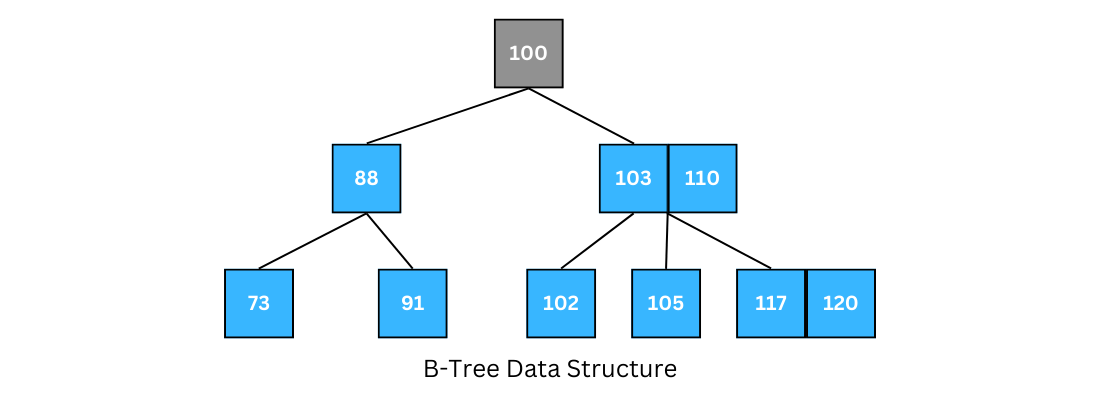
The book Introduction To Algorithms proves that a BTree with a height of 2 and 1,001 children is able to store more than 1 billion keys, and that only 2 disk accesses are required! - with a height of 2:
- The root holds 1,000 (1,001 technically), keys
- Level 1 there are 1,000 nodes (from root) who each have 1,000 keys keys
- Level 2 leaves are total nodes, and so we can store in total keys
- This is roughly shown as , where the root node is counted as one of the 3
BTrees In The Wild
There's several "production grade" implementations of BTree's so that no one has to continue writing their own:
- InnoDB is the general purpose storage engine for MySQL, and has a built in B-Tree index implementation along with many more optimizations
- Also fully supports composite keys where the primary key is the main driver of BTree keys, and further composite keys sort rows lexicographically to create sorted runs that maximize I/O for range scans / point equality lookups
- With
col1, col2, col3composite key,col1is used to sort and traverse the BTree (because of lexicographic sort), andcol2, col3are "tie breakers". If there are 100 pairs ofcol2, col3for a singlecol1value, the BTree itself will have 100 unique keys in it, there isn't a further sub-structure under a node forcol1or anything special
- Lightning Memory-Mapped Database (LMBD) is somewhere between BTree and LSMTree, but overall it stores data in sorted order on disk and holds indexes to them in memory
- SQLite BTree Code can be extracted and reused as a battle-tested BTree implementation you can just copy
Sorting data on disk and using indexes of indexes are useful and common patterns, there's a community of developers out there making each thing faster compared to me trying to write something
Most of these databases can support a BTree on top of some table, like an Orders / Jobs table, where we want to constantly pop off the smallest / next to occur item, while continuously adding in new ones. They maintain theoretical time complexity, and handle all of the disk based I/O
CREATE TABLE priority_queue (
id SERIAL PRIMARY KEY,
payload TEXT, -- Task data
priority INT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
status VARCHAR(20) DEFAULT 'queued' -- 'queued', 'processing', 'done'
);
CREATE INDEX idx_queue_priority ON priority_queue (priority ASC, created_at ASC);
INSERT INTO priority_queue (payload, priority) VALUES ('task_data', 10);
DELETE FROM priority_queue
WHERE id = (
SELECT id FROM priority_queue
ORDER BY priority ASC, created_at ASC
LIMIT 1
FOR UPDATE SKIP LOCKED
);
The above SQL would do a relatively good job at handling these use cases - it's the best case for low to moderate data volumes when strong durability is required over extreme performance. For a high performance priority queue, a Redis based solution is usually preferrable
Usage + Structure
BTree's are mostly just used for, the millionth time, sorted structure and reduced disk access - traversal, searching, inserting, etc
These are the backbones of things like MySQL Indexes, where an index is basically creating a data structure that holds an attribute value and a pointer to a record block on the disk - i.e. a key-pointer pair. Once we generate an index for a relation, we can store the attribute on disk so that each time there's a need to access the record, it can be done by searching these index blocks. The main advantage here is records can be fetched from disk with fewer disk seeks! For an exhaustive search on a linear index like an array, the time required for accessing the required value is of where is the number of blocks that store the index, and in the case of a binary search tree the time required for the search of any entry in the array is reduced to . The number of entries in a node in a BST is restricted to 1, but we can extend this to an m-way search tree where for entries / keys, we can have at most child nodes - this is a k+1-way search tree with k keys. The order of a tree is the maximum number of children that a node in a tree can have, so in a tree of order each node can have a maximum of children and entries, where the entries in each node are sorted. All children in the left subtree of a node have keys less than the parent key's value, and the entries in the right subtree will all be greater
So how is this related to databases? If each node of the tree is a list of pairs containing an attribute value and a pointer to the record that contains that particular attribute value on disk, then the height of the tree determines how many disk seeks we need to perform to find the physical data block holding our data. Each node in the tree can be stored as an index block on the disk itself. Furthermore, m-way search tree's can become unbalanced, and so BTree's look to solve that issue, while keeping things ordered - BTree's are"
- Self balancing
- M-way search trees
- With specific insertion and deletion rules
- Which force every root to leaf path is of the same length
The node structures help to solve this:
- Every internal node has at most children, and an internal node with children has entries
- Each entry in an internal node is
(left child ptr, key value, disk record pointer, right child ptr)keyvalue of an entry is greater than those of all elements in it'sleft childand is lesser than those of all entries inright child
- Each entry in a leaf node is
(key value, disk record pointer) - All leaf nodes appear in the same level, because when a node is full we split them into two such that each node is always at least half full
B+Tree
Creation of a BTree is always done Bottom-Up, where each layer is considered a level of indexing below the above layer
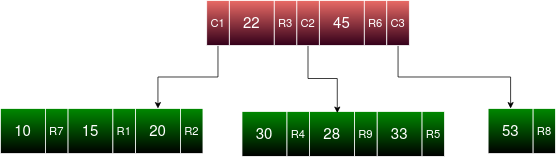
C1, C2, and C3 relate to the child node pointers of the red level, where the red level itself has 2 internal nodes. R1-R9 are the record pointers to the actual records stored on disk somewhere
In a B+ Tree, all record pointers are in leaf nodes! Each leaf node entry in a B+Tree is (key, disk record pointer) similar to a BTree, but in a B+Tree the internal nodes only have (left child ptr, key value, right child ptr). In B+Tree all keys appear in the leaf nodes, which means that a specific entry in a leaf node, upon becoming full and split, is then stored in both the parent node and the leaf node - key values can be replicated in internal nodes and leaf nodes if necessary.
- B-Tree:
- Both internal and leaf nodes store keys and pointers to data (records)
- Internal nodes store keys and pointers to child nodes
- Keys in internal nodes act as separators for the ranges of their children
- Not all keys are guaranteed to be in the leaves; some may only appear in internal nodes
- B+ Tree:
- Only leaf nodes store pointers to data (records)
- Internal nodes store only keys and pointers to child nodes (no data pointers)
- All data records (or pointers to them) are found in the leaf nodes
- All keys are present in the leaves; internal nodes may duplicate keys for routing
- Leaf nodes are connected via a Linked List
So why are B+ Tree's more efficient? It mostly deals with storage space and not having to store extra pointers in the internal nodes, and making search / rotation easier. To calculate the number of keys that can be stored in an internal block of a BTree vs B+Tree with Block Size = 1024 bytes, pointer size = 6 bytes, and key value = 10 bytes:
- BTree
- An entry in an internal node can be considered as a set of a key, disk record pointer, and child pointer so it's size is 10 + 6 + 6 = 22 bytes
- There's an additional child pointer floating around somewhere ( pointers for keys) which is an additional 6
- A single block size is 1024
- B+ Tree
- An entry in an internal node is just key and child pointer so 10 + 6 = 16 bytes
- A single additional floating child pointer
Overall a B+Tree can store more overall keys in it's internal nodes compared to a BTree, which becomes a significant difference as the block size and record pointer size increases. For this to be useful, structuring a node is important so that it can efficiently store nodes in ascending order and hold onto a dynamic representation of the pointers
children[0]points to keyskeys[0]children[1]points to keyskeys[0]andkeys[1]- ...
children[N]points to keyskeys[N-1]
type BTreeNode struct {
keys []int // The keys in this node (sorted)
children []*BTreeNode // Child pointers; len(children) = len(keys) + 1
isLeaf bool // True if this node is a leaf
}
So overall a node is a collection of keys and pointers
Searching
Searching for a key is a generalized form of a Binary Search Tree, where the only main difference is that the BST performs a binary decision, the BTree reduces a number of decisions at each node. The total number of decisions is equal to the number of node's children
| 2 | 8 | 10 |
/ | | \
|1| |6,7| |9| |11, 12|
In a node with keys [2, 8, 10] if we are searching for value 9 we first iterate entirely through that node - we're looking for the first point such that all items are value, and since there are no duplicates it's similar to a bisect_left in Python. The point that's returned, in this case idx=2, is either the key itself in the node or the pointer that would be the correct position to move down
Pseudocode:
- Start from root node
- Compare
lookupwith each of the keys in the current node until there's an entry with keylookup- If found, move to the left child of that entry, if not move to the right most child of the node
- Repeat this process until you reach a leaf node
- Perform a linear search on the leaf node to find key and corresponding value
- If it doesn't exist, stop when key
lookupand returnFalse
- If it doesn't exist, stop when key
Furthermore, once we've reached the child node, we can return a range by doing a linear iteration over items (or binary search of left and right ends of interval) since the leaf nodes are connected via Linked List
Insertion
Inserting involves two steps:
- Traverse down the tree from the root node to find the leaf node where the new entry should go
- If the leaf node is not full, add the entry
- If full (keys over limit of ), split the leaf node
- Allocate a new leaf and move half the elements of the current leaf node to the new leaf node
- Insert a copy of the current leaf node's largest key (median key before split) to the parent
- If the parent is full, split it recursively (start from the top)
- Repeat until a parent is found that doesn't need to be split
- If the root node is split, then a new node is created and the middle key is added to it, and that new node becomes the root nodexw
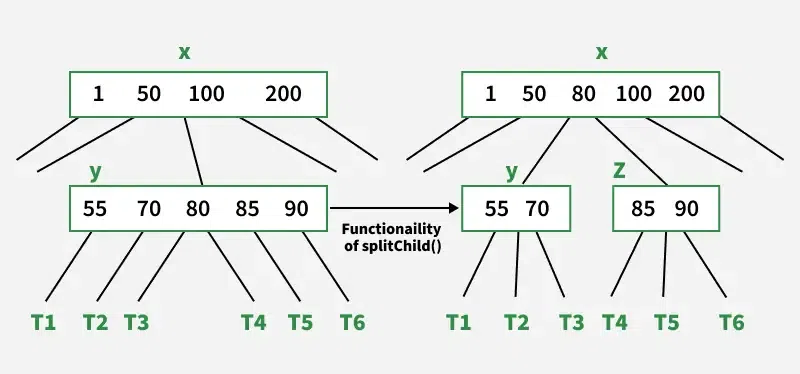
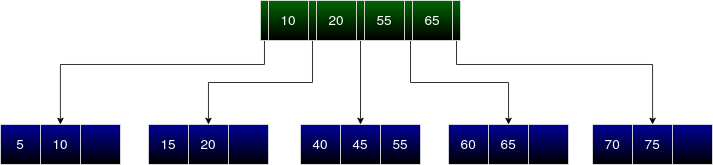
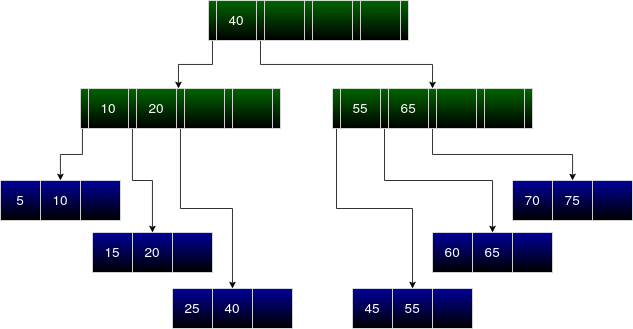
Deletion
Deletion can be done at both leaf or internal node levels, and the algorithm is quite convoluted to do so
- If the node is a leaf node:
- Locate the leaf node containing the key
- If the node has at least keys, delete the key from the leaf node
- If the node has less than keys then take a key from its right or left immediate sibling nodes. This choice can be done as:
- If the left sibling has at least keys, push up the in-order predecessor, the largest key on the left child, to it's parent, and move a proper key from the parent node down to the node containing the key; then delete the key from the node
- If the right sibling has at least keys, push up the in-order successor, the smallest key on the right child, to its parent and move a proper key from the parent node down to the node containing the key; then, we can delete the key from the node
- If the immediate sibligns don't contain keys, create a new leaf node by joining two leaf nodes and the parent node's key
- If the parent is left with less than keys, apply the above process until the tree becomes valid
- If the node is an internal node:
- Replace it with its in order successor or predecessor, since the successor or predecessor will always be on the leaf node, the process will be similar as the node is being deleted from the leaf node
Implementation
The hardest part of implementation is self-balancing. Doing binary search over a sorted tree is easy enough, but self balancing items sitting on disk takes real effort
- Why do nodes split? Because the tree needs to be balanced
- How do nodes split? Splitting, promotion, and a few other tricks, and understanding how a min heap gets heapified is useful!
The difference between B-Tree splits and Min Heap is a lot more though, B-Tree manages pointers to many children, children to parents, parent levels to each other (B+Tree), disk locations, encodings, etc
B-Tree and B+Tree's differ in how they allow for range queries
- B-Tree search can stop at any level, which make range queries harder as you can't do the whole thing
- B+Tree stores data only in leaves, and so range queries, skip list (instead of having to go back up and down tree's), etc is much more efficient, but writes are a bit more convoluted
Self balancing isn't guaranteed out of the box for all indexes! INSERT 1, 2, 3, 4, ... will continuously create tree's with children to the right, and basically create a linked list - random inserts create a balanced tree out of the box. REINDEX helps this out and re-balances other indexes, but BTree's do it automatically out of the box